
 It’s been awhile since I forecast the future of blogs. I am increasingly convinced that what will drive almost all technologies for the foreseeable future is simplicity, disguising under-the-hood sophistication, enabled by elegant design. The digital divide is getting ever-wider, and we need to have tools that will let us more easily pull friends, colleagues and family members who are quickly being left behind, into the information age. As I’ve mentioned before, my father is my benchmark for technology — I can get him to use e-mail (though attachments are a challenge), and Skype, and even to view our daughter’s wedding pictures on Flickr, but not to get a webcam or to participate in online forums. That’s the dividing line that will, I believe, largely determine the future success of technologies, including blogs. What is the simplest way to allow people to ‘publish’ and otherwise share their stuff with others? Drop it in an electronic ‘mailbox’. Bandwidth and storage are now both so cheap that we will soon not care about ‘mailing costs’ or ‘storage costs’ for information, photos, software, or anything else that can be represented in bits. So why not just have a folder that sits on our hard drive for everything we are willing to share with others? Whenever we initially save or change a document, message, or other file, we would be prompted to decide who it could, and who it should, be shared with. It would then be tagged, indexed and permissioned, and a shareable (XML+) version would be created automatically. All of the stuff in the Shareable Stuff folder on our hard drive would be subscribable by others, using the indexing and tags, and subject to permissioning access restrictions we had personally decided on. Google and other search engines would spider it (and probably keep archive copies of it). A viewer trying to access this via a search engine, via a bookmark, or via a subscription, would be able to view it either in the context of other articles with the same index or tags, alphabetically (for browsing), or in reverse chronological order (blog-style, for ‘newsreading’ and getting up to date). Eventually this Shareable Stuff folder might cease to reside on our hard drives entirely (except as a back-up and off-line version) — it could sit out in cyberspace, accessible anytime from any device anywhere. The next stage would be to make this Shareable Stuff collaborative. If I’m reading something from someone else’s Shareable Stuff, I would be able to comment, adapt or annotate it and then, if I’m appropriately permissioned by the original author(s), those additions and changes (appropriately ‘signed’ to show they were from me) would be made to the authors’ ‘original’ version. Alternatively, if I just want to annotate or change it for my own purposes, my ‘copy’ (with the original authors identities or ‘signatures’ maintained) would be added to my own Shareable Stuff folder. It would, in turn, be accessible by those I have permissioned to view my Shareable Stuff folder, and they might further annotate it. This would create wiki-style collections of stuff that would ultimately become ‘collectively’ owned — each of the ‘collective’ owners would have their own copies with any private annotations they did not want to share, but there would be an emergent ‘collective’ collection that would in effect be owned jointly, with each of the members agreeing to honour a particular indexing, tagging and permissioning protocol for the collection that might, for example, allow (a) anyone to subscribe, (b) only certain specified people to append comments, and (c) only members to edit or change. The ‘official’ copy could reside anywhere (it would be any member’s copy minus that member’s ‘private’ annotations). I know this sounds complicated, but all this detail would be hidden under the hood, invisible to the individual writer or reader. From their perspective, it couldn’t be simpler:
Defaults would usually make this decision as simple as clicking ‘OK’, drawing on the indexing, tags and permissioning that applied the last time you saved the file, or those that were suggested by the initial author of the document or message, or the permissioning you have assigned to other files with the same index or tags.
So in an extreme case, you could simply make all your stuff available to anyone who was interested. Your entire hard drive would then become (a) a filing cabinet — in the form of a huge wiki — open to the public to browse and (b) a weblog documenting everything you write as you write it. You wouldn’t have to do a thing except write (or draw, or podcast, or whatever it is you do to communicate and record your stuff). No need to set up and maintain separate weblogs or wikis, no need to ‘publish’ anything, no need to keep e-mails in a different format from anything else you write. No need to worry about different formats at all. The system would automatically ‘blackline’ the changes and annotations you made to any file since your last ‘save’ so that people who should or could read them get to see precisely what changes you have made in context, and don’t need to re-read the entire file. You may have noted that this ‘system’ uses the ‘save’ command as the trigger to share stuff. And of course we don’t just ‘save’ when we’re finished writing. We ‘save’ often because of the shoddy and unreliable hardware and software we are forced to use by the technology vendor oligopolies (sorry, I couldn’t resist). So we would need to differentiate between ‘save in case the system crashes’ and ‘save because we’re done writing’. Maybe we call these ‘save’ and ‘done’ respectively. My father could handle this. With this system, everyone becomes a blogger and a wiki writer, just by writing in whatever applications they’re comfortable with. In fact a single meta-application, a kind of superwiki, could be developed for producing bits in any format, with all the underlying applications and translation code shoved under the hood where the end user needn’t worry about them. You know who could rather easily do all this for us, of course. I’ll give you a hint — their name starts with a G. Cartoon above is from this week’s New Yorker by ex-National Lampooner PC Vey. It brilliantly and poignantly captures what all of us (and our spouses) felt and feared when we started blogging (and sometimes still do). I’m getting it as a sweatshirt to go along with my Alex Gregory dog cartoon. Get your favourite New Yorker cartoons as prints or apparel here. Cartoonists need our support. |
Navigation
Collapsniks
Albert Bates (US)
Andrew Nikiforuk (CA)
Brutus (US)
Carolyn Baker (US)*
Catherine Ingram (US)
Chris Hedges (US)
Dahr Jamail (US)
Dean Spillane-Walker (US)*
Derrick Jensen (US)
Dougald & Paul (IE/SE)*
Erik Michaels (US)
Gail Tverberg (US)
Guy McPherson (US)
Honest Sorcerer
Janaia & Robin (US)*
Jem Bendell (UK)
Mari Werner
Michael Dowd (US)*
Nate Hagens (US)
Paul Heft (US)*
Post Carbon Inst. (US)
Resilience (US)
Richard Heinberg (US)
Robert Jensen (US)
Roy Scranton (US)
Sam Mitchell (US)
Tim Morgan (UK)
Tim Watkins (UK)
Umair Haque (UK)
William Rees (CA)
XrayMike (AU)
Radical Non-Duality
Tony Parsons
Jim Newman
Tim Cliss
Andreas Müller
Kenneth Madden
Emerson Lim
Nancy Neithercut
Rosemarijn Roes
Frank McCaughey
Clare Cherikoff
Ere Parek, Izzy Cloke, Zabi AmaniEssential Reading
Archive by Category
My Bio, Contact Info, Signature Posts
About the Author (2023)
My Circles
E-mail me
--- My Best 200 Posts, 2003-22 by category, from newest to oldest ---
Collapse Watch:
Hope — On the Balance of Probabilities
The Caste War for the Dregs
Recuperation, Accommodation, Resilience
How Do We Teach the Critical Skills
Collapse Not Apocalypse
Effective Activism
'Making Sense of the World' Reading List
Notes From the Rising Dark
What is Exponential Decay
Collapse: Slowly Then Suddenly
Slouching Towards Bethlehem
Making Sense of Who We Are
What Would Net-Zero Emissions Look Like?
Post Collapse with Michael Dowd (video)
Why Economic Collapse Will Precede Climate Collapse
Being Adaptable: A Reminder List
A Culture of Fear
What Will It Take?
A Future Without Us
Dean Walker Interview (video)
The Mushroom at the End of the World
What Would It Take To Live Sustainably?
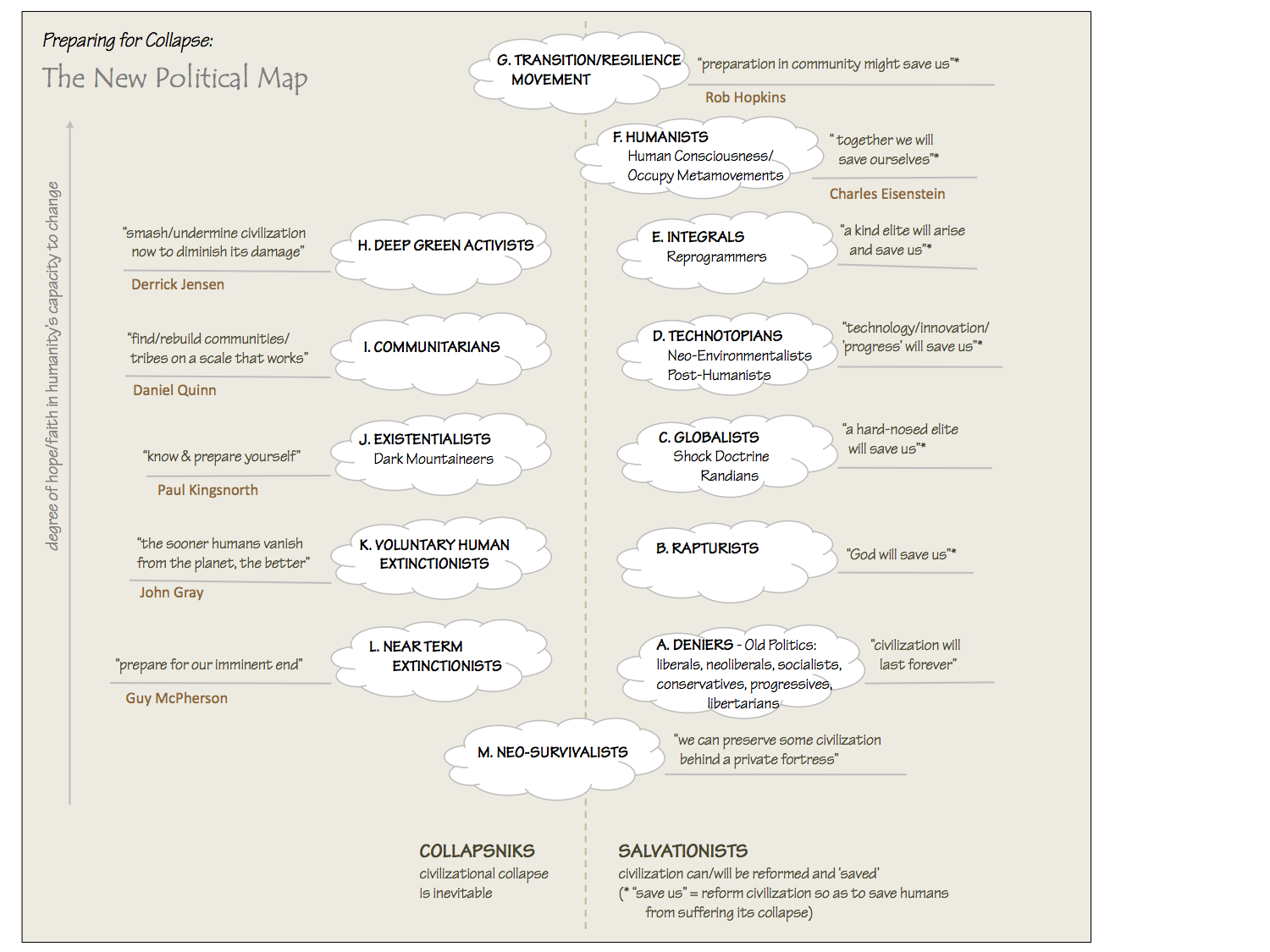
The New Political Map (Poster)
Beyond Belief
Complexity and Collapse
Requiem for a Species
Civilization Disease
What a Desolated Earth Looks Like
If We Had a Better Story...
Giving Up on Environmentalism
The Hard Part is Finding People Who Care
Going Vegan
The Dark & Gathering Sameness of the World
The End of Philosophy
A Short History of Progress
The Boiling Frog
Our Culture / Ourselves:
A CoVid-19 Recap
What It Means to be Human
A Culture Built on Wrong Models
Understanding Conservatives
Our Unique Capacity for Hatred
Not Meant to Govern Each Other
The Humanist Trap
Credulous
Amazing What People Get Used To
My Reluctant Misanthropy
The Dawn of Everything
Species Shame
Why Misinformation Doesn't Work
The Lab-Leak Hypothesis
The Right to Die
CoVid-19: Go for Zero
Pollard's Laws
On Caste
The Process of Self-Organization
The Tragic Spread of Misinformation
A Better Way to Work
The Needs of the Moment
Ask Yourself This
What to Believe Now?
Rogue Primate
Conversation & Silence
The Language of Our Eyes
True Story
May I Ask a Question?
Cultural Acedia: When We Can No Longer Care
Useless Advice
Several Short Sentences About Learning
Why I Don't Want to Hear Your Story
A Harvest of Myths
The Qualities of a Great Story
The Trouble With Stories
A Model of Identity & Community
Not Ready to Do What's Needed
A Culture of Dependence
So What's Next
Ten Things to Do When You're Feeling Hopeless
No Use to the World Broken
Living in Another World
Does Language Restrict What We Can Think?
The Value of Conversation Manifesto Nobody Knows Anything
If I Only Had 37 Days
The Only Life We Know
A Long Way Down
No Noble Savages
Figments of Reality
Too Far Ahead
Learning From Nature
The Rogue Animal
How the World Really Works:
Making Sense of Scents
An Age of Wonder
The Truth About Ukraine
Navigating Complexity
The Supply Chain Problem
The Promise of Dialogue
Too Dumb to Take Care of Ourselves
Extinction Capitalism
Homeless
Republicans Slide Into Fascism
All the Things I Was Wrong About
Several Short Sentences About Sharks
How Change Happens
What's the Best Possible Outcome?
The Perpetual Growth Machine
We Make Zero
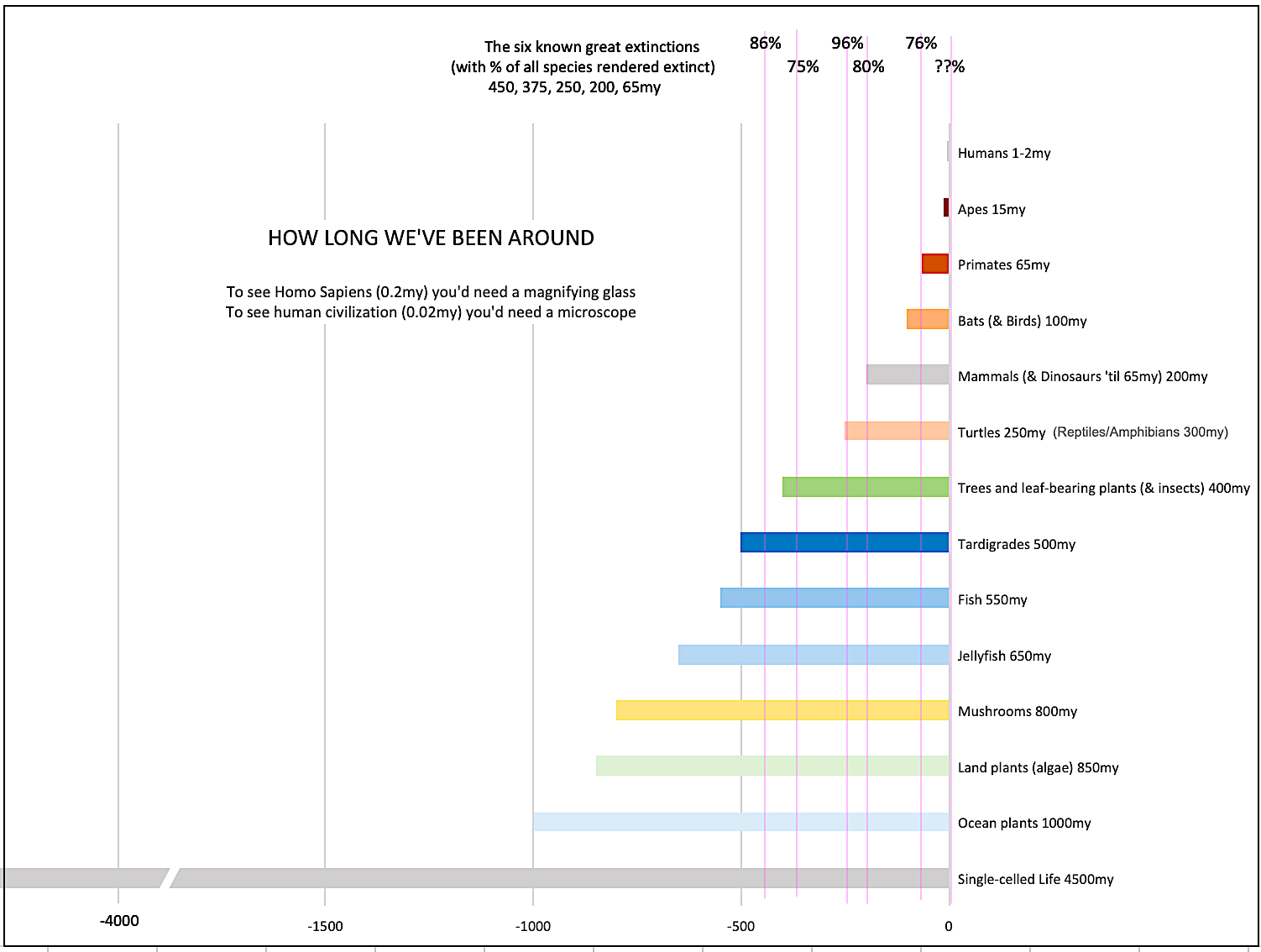
How Long We've Been Around (graphic)
If You Wanted to Sabotage the Elections
Collective Intelligence & Complexity
Ten Things I Wish I'd Learned Earlier
The Problem With Systems
Against Hope (Video)
The Admission of Necessary Ignorance
Several Short Sentences About Jellyfish
Loren Eiseley, in Verse
A Synopsis of 'Finding the Sweet Spot'
Learning from Indigenous Cultures
The Gift Economy
The Job of the Media
The Wal-Mart Dilemma
The Illusion of the Separate Self, and Free Will:
No Free Will, No Freedom
The Other Side of 'No Me'
This Body Takes Me For a Walk
The Only One Who Really Knew Me
No Free Will — Fightin' Words
The Paradox of the Self
A Radical Non-Duality FAQ
What We Think We Know
Bark Bark Bark Bark Bark Bark Bark
Healing From Ourselves
The Entanglement Hypothesis
Nothing Needs to Happen
Nothing to Say About This
What I Wanted to Believe
A Continuous Reassemblage of Meaning
No Choice But to Misbehave
What's Apparently Happening
A Different Kind of Animal
Happy Now?
This Creature
Did Early Humans Have Selves?
Nothing On Offer Here
Even Simpler and More Hopeless Than That
Glimpses
How Our Bodies Sense the World
Fragments
What Happens in Vagus
We Have No Choice
Never Comfortable in the Skin of Self
Letting Go of the Story of Me
All There Is, Is This
A Theory of No Mind
Creative Works:
Mindful Wanderings (Reflections) (Archive)
A Prayer to No One
Frogs' Hollow (Short Story)
We Do What We Do (Poem)
Negative Assertions (Poem)
Reminder (Short Story)
A Canadian Sorry (Satire)
Under No Illusions (Short Story)
The Ever-Stranger (Poem)
The Fortune Teller (Short Story)
Non-Duality Dude (Play)
Your Self: An Owner's Manual (Satire)
All the Things I Thought I Knew (Short Story)
On the Shoulders of Giants (Short Story)
Improv (Poem)
Calling the Cage Freedom (Short Story)
Rune (Poem)
Only This (Poem)
The Other Extinction (Short Story)
Invisible (Poem)
Disruption (Short Story)
A Thought-Less Experiment (Poem)
Speaking Grosbeak (Short Story)
The Only Way There (Short Story)
The Wild Man (Short Story)
Flywheel (Short Story)
The Opposite of Presence (Satire)
How to Make Love Last (Poem)
The Horses' Bodies (Poem)
Enough (Lament)
Distracted (Short Story)
Worse, Still (Poem)
Conjurer (Satire)
A Conversation (Short Story)
Farewell to Albion (Poem)
My Other Sites




{kind=link}
{kind=link}
Umm…hold that thought. How do you think this scenario would change if new technology emerged within the year that made wireless high-speed internet nearly pervasive?Do you think we’d still want to go to an access point like a computer to do this?
http://www.usemod.com/cgi-bin/mb.pl?NetworkRepositoryWhy is the file menu still paper orientated? Why doesn’t it have a “Checkout from Repository…” and a “Commit to Repository…”? And why doesn’t it have a “Publish to Website…”?
‘save in case the system crashes’ isn’t necessary with modern computers. Every file should be saved every keystroke, and keep its undo history. ‘save because we’re done writing’ is what Alan Cooper (author of About Face, a usability book from a decade ago which covers this subject) calls making a ‘milestone’. Which in turn is really ‘commit to repository’, or in the blog world ‘publish’.There are lots of concepts converging together here, and a simple interface to it that nobody has yet discovered.I’m very sceptical about tagging, I think it would terrify and confuse my mother. Full text search should be good enough. Or maybe a simple “description” field where you write an extra textual description of the document if necessary, which also gets searched. Tags are just words, so if you want to specifically mark specific documents you could still write those words in the description.
I’d much rather read a well-organized blog than wade through someone’s “folder of stuff”.If publishing requires no thought and no effort, the quality of the published material tends towards junk.
This is already available through several services. FolderShare is one well known version (I believe Microsoft bought them recently).There is another version that runs through Skype, but I forget the name.While they are not open to the general public (only to invited members), it is the first step to what you are talking about.
I remember when you mentioned something about this in the past as far as a personal desktop/knowledge management tool and it caused me to do a bunch of thinking about the subject. You hadn’t really defined it in detail back then, besides at the user level. What you’ve come up with is similar to what I’ve been toying with in my head. To respond to Francis, Tags are absolutely essential. I don’t think that they need to be part of the front end user experience, but they need to be part of the backend structure. They are necessary because they are used to store data that isn’t intrinsic in the native file format. They could be anything from just documenting where the user highlights the text to important results that a filter would come up with after scouring the file.I think in the grand long term vision, this type of program would eventually get broken down into classifying things as “ideas” or “thoughts” in an effort to replicate how the brain stores information. Each thought could be classified by another thought or pattern to help give context and ability to different search engines or filtering programs. You could have a program that could read all your thoughts to determine what all the subjects and objects you were referring to were and then automatically start noticing commonalities. People could automatically be linked to other people based on if the computer noticed similar patterns in how they speaked or what their frames were (the frames part would be tough to develop, but in due time it could be accomplished). People could be linked to other people who were into conversing about such and such. Search engines could be so much more effective at providing relevant data if they knew the context the documents came from rather than just bulk scanning the document to begin with.You could have software that read all your posts and started creating a mental list of all the objects you used even if they were indirectly mentioned like, “I think he is a very bad president.” where the software would be able to determine from context that he is in reference to Bush or the like.
What you describe sounds a lot like what Taligent was developing, years ago, and what was partially implemented in Apple’s OpenDoc. Document “saving” was being largely eliminated as a user operation, along with applications. Instead, a document-oriented editing environment, made up of editing components, was being created. In some of the patents and other public documents, Taligent implied that documents would be saved automatically with unlimited undos, and that the undos would be persistent across sessions (unlike today, where “unlimited undo” stops when you quit the application, or even when you save the document). Taligent/OpenDoc had its problems, not least of which was debugging, but Apple is still implementing some of the ideas from Taligent in Mac OS X.I think the tags might be useful to advanced users, but for most users, I agree with Francis Irving. Luckily, data mining and search technologies have come far enough that tags should not be necessary. Algorithmically identifying similarities between documents (not only content, but also things like where they’re saved, who created them, who has viewed and who has edited them, and when they were created and edited) would provide much–though not quite all–of the functionality provided by tags, and do it transparently. Desktop search technologies like Searchlight and Google Desktop Search are (slowly) progressing in this direction.It is interesting to note, too, that Windows and Mac OS X both allow sharing of folders over networks and provide some limited support of collaborative work. It seems logical to expect this functionality to grow with time, as you have outlined, and the above technologies provide some of the framework necessary to make it work.I’m still waiting for RAM that does not loose its state when powered down; that would largely allow the complete elimination of saving. The OS would just have to make periodic copies of RAM on a hard drive for emergencies.
Rayne: Interesting point. I think there’s a race on — whether small, powerful portable PCs will prevail, making it easy to just cart ‘content’ around with us; or whether high bandwidth will prevail, so we’ll just use whatever ‘appliance’ is nearby wherever we are to get content from a central server in cyberspace. Gideon: Good questions. That’s certainly another way of doing it.Francis: I agree on both scores.Helen: Hmmm..I wonder. I have tremendous ‘pride of ownership’ of stuff that has my name attached to it (much more than to stuff that gets sent anonymously into a centralized database). I think reputation is so important that people will avoid publishing garbage to prevent getting a reputation for poor quality writing, which reputation will spread fast enough and be so pervasive that they will never again be able to get an audience. Hell, it’s hard enough getting an audience in the first place to risk it by publishing crap.Mooby: Good to know it’s coming. Medaille: Could applications be designed to be intelligent enough to do ‘tagging’ automatically? I keep coming back to the filing cabinet analogy — let me into the filing cabinet of the company’s Subject Matter Expert and I’ll be willing to browse it, no matter how it’s organized, until I find what I’m looking for, and probably read some other stuff serendipitously as well.Tom: Heh, there are a few applications that save automatically and have no separate ‘save’ command — we’re so used to it that it’s terrifying not to have it.
sky lopezsky lopezsky lopez http://skylopez.crearforo.com sky lopez
http://www.forumage.com/index.php?mforum=kaysjewelry kays jewelry kays jewelry
http://xoomer.alice.it/replicas/rolex-replica.html rolex replica rolex replica
http://xoomer.alice.it/replicas/rolex-replicas.html rolex replicas rolex replicas