
 I‘ve been waiting for Google, which has already provided a definitive ‘know-what’ information finder and ‘know-where’ place finder, to follow up with the definitive ‘know-who’ people-finder. My initial thought was that only Google and one or two other giants could get enough profile with this to get everyone to participate and accept it as the standard, and hence achieve the critical mass to succeed where so many Social Networking tools that have tried to do this have failed. But then it occurred to me that there is a profound difference between ‘know-what’ and ‘know-where’ on the one hand, and ‘know-who’ on the other: Finding the former are complicated search problems; finding the latter is a complex problem. Google can write an algorithm to point you to the documents most likely to be useful to you on subject x, and they can create maps to point you to location y. You don’t have to do anything but ask. And although the numbers are vast, there are only a finite number of documents and places on the planet. By contrast, any meaningful people-finder would require active and regular participation of many people. Assessments of expertise are too subjective and change too quickly over time for any kind of algorithm to ‘interpret’ from data that are already ‘out there’. But any kind of top-down, managed expertise-finder will inevitably fall victim to the same problems that have afflicted Linked-In and other social networking apps: Not broad enough participation, data that is stale and which no one is motivated to keep current, and the tendency of people to try to ‘game’ the system to portray themselves as more popular and expert than they really are. The only thing that will work, I believe, is a Peer-to-Peer solution, one that works with existing ubiquitous tools and which makes it easy for anyone, regardless of what platform they are working on, to participate with little or no incremental effort. When addressing any complex problem, we need to give the solution the opportunity to evolve as the result of the collective intelligence of everyone. That is an imposing challenge but not an impossible one. What we need to do first is develop a high-level spec for a system that no one will build. The spec will be merely the initial set of principles and guidelines that will influence how we participate. The ‘crowd’ will tell us if some of those principles and guidelines are wrong, and what’s missing, and we’ll change them to reflect that wisdom and imagination. Here’s my first cut at some of those principles and guidelines. We need the people who know the Internet best, both as a technical and social phenomenon, to add to this list — we won’t get it ‘right’ the first time, but the closer we get the list in the early stages (or, to use complexity terminology, the more valuable our initial set of attractors and barriers), the faster something useful will start to emerge from it.
I can see this evolving in interesting ways. Corporations will initially want to use this within their Intranet firewalls to find experts within their own organizations, and won’t want that data accessible outside the firewall. But information is always trying to be free, and once smaller organizations ‘let it out’, and buyers start looking for and expecting to see their preferred suppliers’ experts’ names showing up on ‘know-who’ search results, the big professional firms will have no choice but to open up the data to the world and let buyers start putting together their own cross-organizational teams of experts. I also think that being acknowledged as an expert is a double-edged sword, and such a system will start to create genuine ‘markets’ for expertise. People acknowledged as experts who are bombarded with requests for their expertise, and who cannot afford (or do not want) to spend their whole life sharing what they know free, will naturally start to put in personal, market-driven hourly rates for their expertise, and hence filter out most of the requests. Who knows, some of us might find that we’re acknowledged as experts by more people than we think, and we might even be able to make a living simply on the strength of this system’s ‘word of mouth’. It sounds very complex and unmanageable, I know, and it is, which is probably why it hasn’t happened already. But there is a clear need for a viable, simple, reliable, easy-to-maintain expertise finder, and once a few million people agree to start maintaining the information that would drive it, I think it could explode quite quickly, and evolve just as quickly to meet this need extremely well. The key is not to try to design a centrally-managed app for it, but rather to let it grow and become what it will become, virally and organically. I’m going to pass my thoughts along to Doc and David W. for a start (since I recognize their expertise in this area as ‘H’). If you think this is a useful avenue for exploration, please talk it up and tell me what you, and others youtalk to, think. |
Navigation
Collapsniks
Albert Bates (US)
Andrew Nikiforuk (CA)
Brutus (US)
Carolyn Baker (US)*
Catherine Ingram (US)
Chris Hedges (US)
Dahr Jamail (US)
Dean Spillane-Walker (US)*
Derrick Jensen (US)
Dougald & Paul (IE/SE)*
Erik Michaels (US)
Gail Tverberg (US)
Guy McPherson (US)
Honest Sorcerer
Janaia & Robin (US)*
Jem Bendell (UK)
Mari Werner
Michael Dowd (US)*
Nate Hagens (US)
Paul Heft (US)*
Post Carbon Inst. (US)
Resilience (US)
Richard Heinberg (US)
Robert Jensen (US)
Roy Scranton (US)
Sam Mitchell (US)
Tim Morgan (UK)
Tim Watkins (UK)
Umair Haque (UK)
William Rees (CA)
XrayMike (AU)
Radical Non-Duality
Tony Parsons
Jim Newman
Tim Cliss
Andreas Müller
Kenneth Madden
Emerson Lim
Nancy Neithercut
Rosemarijn Roes
Frank McCaughey
Clare Cherikoff
Ere Parek, Izzy Cloke, Zabi AmaniEssential Reading
Archive by Category
My Bio, Contact Info, Signature Posts
About the Author (2023)
My Circles
E-mail me
--- My Best 200 Posts, 2003-22 by category, from newest to oldest ---
Collapse Watch:
Hope — On the Balance of Probabilities
The Caste War for the Dregs
Recuperation, Accommodation, Resilience
How Do We Teach the Critical Skills
Collapse Not Apocalypse
Effective Activism
'Making Sense of the World' Reading List
Notes From the Rising Dark
What is Exponential Decay
Collapse: Slowly Then Suddenly
Slouching Towards Bethlehem
Making Sense of Who We Are
What Would Net-Zero Emissions Look Like?
Post Collapse with Michael Dowd (video)
Why Economic Collapse Will Precede Climate Collapse
Being Adaptable: A Reminder List
A Culture of Fear
What Will It Take?
A Future Without Us
Dean Walker Interview (video)
The Mushroom at the End of the World
What Would It Take To Live Sustainably?
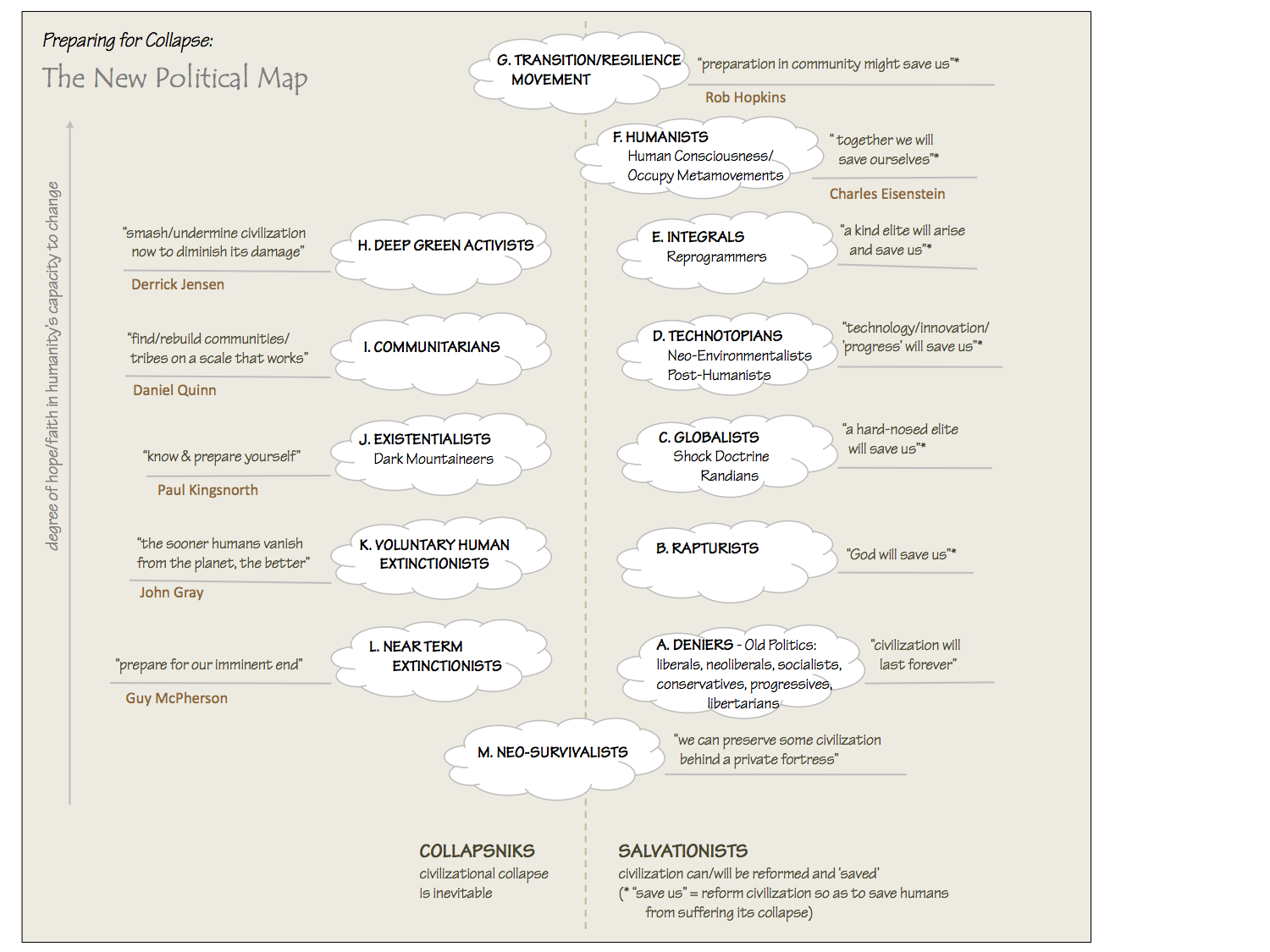
The New Political Map (Poster)
Beyond Belief
Complexity and Collapse
Requiem for a Species
Civilization Disease
What a Desolated Earth Looks Like
If We Had a Better Story...
Giving Up on Environmentalism
The Hard Part is Finding People Who Care
Going Vegan
The Dark & Gathering Sameness of the World
The End of Philosophy
A Short History of Progress
The Boiling Frog
Our Culture / Ourselves:
A CoVid-19 Recap
What It Means to be Human
A Culture Built on Wrong Models
Understanding Conservatives
Our Unique Capacity for Hatred
Not Meant to Govern Each Other
The Humanist Trap
Credulous
Amazing What People Get Used To
My Reluctant Misanthropy
The Dawn of Everything
Species Shame
Why Misinformation Doesn't Work
The Lab-Leak Hypothesis
The Right to Die
CoVid-19: Go for Zero
Pollard's Laws
On Caste
The Process of Self-Organization
The Tragic Spread of Misinformation
A Better Way to Work
The Needs of the Moment
Ask Yourself This
What to Believe Now?
Rogue Primate
Conversation & Silence
The Language of Our Eyes
True Story
May I Ask a Question?
Cultural Acedia: When We Can No Longer Care
Useless Advice
Several Short Sentences About Learning
Why I Don't Want to Hear Your Story
A Harvest of Myths
The Qualities of a Great Story
The Trouble With Stories
A Model of Identity & Community
Not Ready to Do What's Needed
A Culture of Dependence
So What's Next
Ten Things to Do When You're Feeling Hopeless
No Use to the World Broken
Living in Another World
Does Language Restrict What We Can Think?
The Value of Conversation Manifesto Nobody Knows Anything
If I Only Had 37 Days
The Only Life We Know
A Long Way Down
No Noble Savages
Figments of Reality
Too Far Ahead
Learning From Nature
The Rogue Animal
How the World Really Works:
Making Sense of Scents
An Age of Wonder
The Truth About Ukraine
Navigating Complexity
The Supply Chain Problem
The Promise of Dialogue
Too Dumb to Take Care of Ourselves
Extinction Capitalism
Homeless
Republicans Slide Into Fascism
All the Things I Was Wrong About
Several Short Sentences About Sharks
How Change Happens
What's the Best Possible Outcome?
The Perpetual Growth Machine
We Make Zero
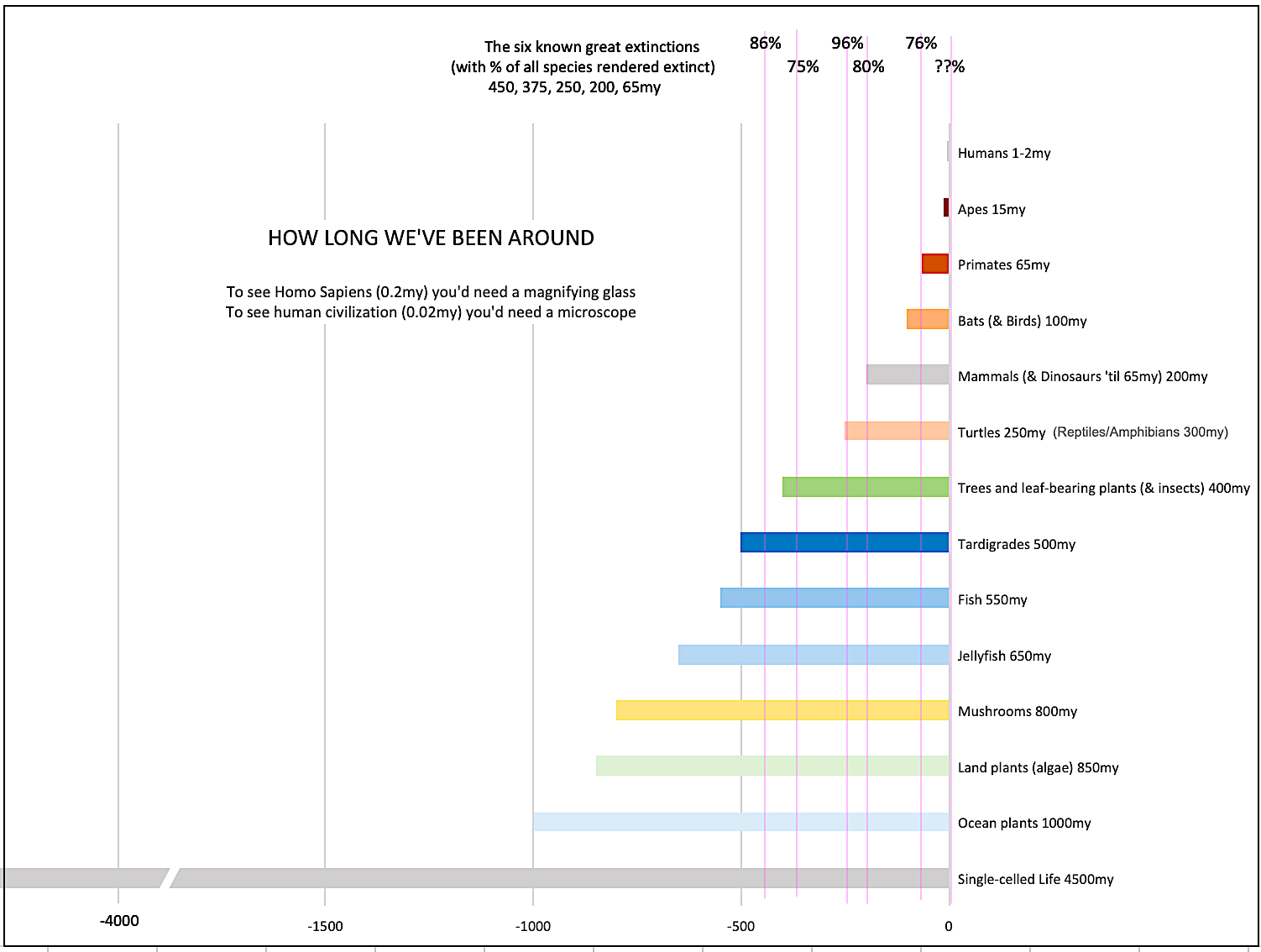
How Long We've Been Around (graphic)
If You Wanted to Sabotage the Elections
Collective Intelligence & Complexity
Ten Things I Wish I'd Learned Earlier
The Problem With Systems
Against Hope (Video)
The Admission of Necessary Ignorance
Several Short Sentences About Jellyfish
Loren Eiseley, in Verse
A Synopsis of 'Finding the Sweet Spot'
Learning from Indigenous Cultures
The Gift Economy
The Job of the Media
The Wal-Mart Dilemma
The Illusion of the Separate Self, and Free Will:
No Free Will, No Freedom
The Other Side of 'No Me'
This Body Takes Me For a Walk
The Only One Who Really Knew Me
No Free Will — Fightin' Words
The Paradox of the Self
A Radical Non-Duality FAQ
What We Think We Know
Bark Bark Bark Bark Bark Bark Bark
Healing From Ourselves
The Entanglement Hypothesis
Nothing Needs to Happen
Nothing to Say About This
What I Wanted to Believe
A Continuous Reassemblage of Meaning
No Choice But to Misbehave
What's Apparently Happening
A Different Kind of Animal
Happy Now?
This Creature
Did Early Humans Have Selves?
Nothing On Offer Here
Even Simpler and More Hopeless Than That
Glimpses
How Our Bodies Sense the World
Fragments
What Happens in Vagus
We Have No Choice
Never Comfortable in the Skin of Self
Letting Go of the Story of Me
All There Is, Is This
A Theory of No Mind
Creative Works:
Mindful Wanderings (Reflections) (Archive)
A Prayer to No One
Frogs' Hollow (Short Story)
We Do What We Do (Poem)
Negative Assertions (Poem)
Reminder (Short Story)
A Canadian Sorry (Satire)
Under No Illusions (Short Story)
The Ever-Stranger (Poem)
The Fortune Teller (Short Story)
Non-Duality Dude (Play)
Your Self: An Owner's Manual (Satire)
All the Things I Thought I Knew (Short Story)
On the Shoulders of Giants (Short Story)
Improv (Poem)
Calling the Cage Freedom (Short Story)
Rune (Poem)
Only This (Poem)
The Other Extinction (Short Story)
Invisible (Poem)
Disruption (Short Story)
A Thought-Less Experiment (Poem)
Speaking Grosbeak (Short Story)
The Only Way There (Short Story)
The Wild Man (Short Story)
Flywheel (Short Story)
The Opposite of Presence (Satire)
How to Make Love Last (Poem)
The Horses' Bodies (Poem)
Enough (Lament)
Distracted (Short Story)
Worse, Still (Poem)
Conjurer (Satire)
A Conversation (Short Story)
Farewell to Albion (Poem)
My Other Sites




{kind=link}
{kind=link}
I’ve done some thinking on this issue, and while I don’t consider myself an expert at computer programming or software design, I do have a good feel for what I would like to see in this arena. The biggest thing that I see differently then what I think you are seeing, is that I think the (expert finder, the group collaboration tools, the personal desktop [all of which you’ve talked about]), as well as some other things such as a media exchanger (like for local news) and other similarly defined things (directory service, like craigslist) should all be lumped into one tool.There are a couple of reasons as to why this should be lumped into one tool rather than having several stand alone tools. The first and most important is that there needs to be a method of managing interactions between people. In my mind, the current method of specific tools being made for specific needs is very chaotic. I generally consider myself to be a year and a half behind the progressive edge of computer technology, so if I find it annoying to have to continually search out new tools so I can find like minds then other less technologically-able people probably just completely ignore the bulk of it and thus would be missing out as well as the network would be missing out on them. To me, it makes sense that the people and how they group themselves by the result they desire to obtain should be the first priority and everything should branch from that, rather than the tools defining the group structure. I would be fine if it was as simple as something like myspace, but with some tweaks to fit in tightly with the rest of the system. There needs to be one place for all the people to be grouped to make the network more able.Another reason is that it just makes sense that once you have all your connections able to be usable to have access to being able to do something with them, without them having to download a certain interface that they aren’t amiliar with just to work and discuss with you. As an example, I wouldn’t want to have to teach someone how to install and use skype just to communicate with them, and I certainly wouldn’t want to try to manage 18 different tools in that manner just to work with them.For the most part, almost all items are defined in similar manners. There are only so many common methods of information exchange. You only have 2 of the five senses to worry about, time interactions, spatial occupancy, user modification, and publication type to worry about and they can be combined in different ways. To start out with, you could choose to only exchange words (in audio or text) and/or images (video, 2d documents), etc. I know there are some things that get outside of that box, but mostly, tools stay in there. This means that a lot of tools are redundant under the hood, despite differences in the surface of the way they interact with it. It makes sense to me to have some sort of framework to house everything. Kind of like how mozilla has extensions.On a similar note, the means of sorting something are similar and google isn’t providing a completely adequate solution yet. The biggest drawback is the lack of locality being integrated into all networking tools. While it is nice to have the full internet at your disposal, its sheer girth makes it difficult to get in touch with people you can physically interact with if you so desire. Social interaction/collaboration tools should have a map integrated into them in order to easily visualize and sort experts etc.——————————–This is some half formulated concept in my head, and thus I can visualize it better than I can explain it, so its probably sounding fairly scattered. I do have some general thoughts on this whole issue in its broad context. All users need to be have some sort of privacy/encryption built in. They need to be assured that they are free to exchange information in whatever way they would like. It’s of no use if the FBI, CIA, RIAA,or any other group/person can start intimidating people based on what they are sharing. Freedom of information is a strength of the network and the government recinding/infringing on those rights should not be tolerated if it can be helped.Decentralization vs. Centralization. This is something that isn’t so black and white. From Illich (Tools of Conviviality), we know that there are two watersheds as we progress from diverse systems to industrialized systems. I think the goal, obviously is to stay between the two watersheds. Right now the internet is too decentralized and its productivity is hindered. At some point in time, the limitations of using a thoroughly centralized tool start to outweigh the benefits. The goal is to create tools that are flexible enough to empower people but not to limit them. On the other hand, centralization in proper doses does increase productivity. Nature teaches us that there is reliability, safety, and value in diversification. Natures timescale isn’t exactly our friend though as evolution is a relatively slow process and when you force human hands into the creation process things can quickly get disordered like entropy (for both better and worse) if there’s not some sort of central guiding hand to try to keep order from disorder. Our tools need to self-regulate and keep order and prevent disorder. That’s a given. It is more time efficient to achieve the social change we desire, by preventing tools from creating excessive disorder.What is the main purpose of peer-to-peer collaboration tools? The main purpose is to remove power from where it is centralized and send it back to all the people equally. That’s the whole point of blogs, indymedia, etc. Corporate controlled information exchange has stopped being beneficial and is being used in a manner that is artificially limiting what people CAN be exposed to. In all aspects of life, we need to be reclaiming out power and enhancing our power. Proper information exchange allows people to be empowered which is the complete antithesis of what they are now. It is a crucial building block to sustainability.
Hi, I understand what you are saying, and the vast issues associated with it. On the other hand, it could be argued that Squidoo (www.squidoo.com) is an attempt to provide one part of the answer. On the other hand, the existence of a squidoo lens doesn’t guarantee that the lens owner is the appropriate expert, but they _could_ be the facilitator – the person who can facilitate access to that expertise.Just a thought…David
Have you looked at FOAF?
Do you remembver something called XpertWeb, developed by Britt Blaser ? britt is a friend of doc’s, as well. I think the technology is just sitting there, and it was / is fundamentally peer – to -peer.Here’s the URL, with some information and a whole bunch of flow charts / diagrams … http://www.xpertweb.com
Here’s the first few words that greet you on the site … I think this is more or less what you are wondering about / looking for:Welcome to XpertwebJoy’s Law: “The best expert for your most important project …… doesn’t work in your company.”- Bill Joy, Co-Founder, Sun MicroSystemsAn open source co-op to connect you directly with the best experts available.
The best way to accomplish the voting would not be by having people actually rate how much attention they THINK they would give to someone. Rather, devise a way to measure how much attention someone actually gets. People are terrible at estimating how much they WOULD do. It takes enough effort just to vote that they would tend to only vote when they would either invest a lot of time or no time.I had an idea several years back that was remarkably similar to del.icio.us but it had am insurmountable flaw. I wanted people to rate the URLs. Then the system would let you find people with tastes similar to yours and you could get a reading for whether a URL was likely to be interesting to you.The problem was the effort involved in rating URLs. The genious behind del.icio.us is the realization that by giving people the “service” of saving their bookmarks in a central location where they could access them from any machine that happened to be handy, they got the rating system as a side effect. If something is cool enough that a lot of people bookmark it, then there is your rating. Then the power users discovered that you could find people that linked to stuff you liked and browse their public bookmarks and find other stuff you liked. Viola! The system I was looking for with minimal effort. Folks are falling all over themselves to rank the links for you because you are supplying them with something they want at the same time.
Email us via our company email account(allphonesltd1@yahoo.co.uk) (allphonesltd1999@hotmail.com) phonesNokia N91 220$Nokia 6060 145$Nokia 6111 132$Nokia 6270 125$Nokia 6270 115$Nokia 6280 125$Nokia N90 115$Nokia N70 115$Nokia Vertu 200$ (allphonesltd1@yahoo.co.uk)Nokia 5140i 125$ (allphonesltd1999@hotmail.com)Nokia 6230i 115$Nokia 8800 200$Nokia 6021 105$Nokia 6030 115$Nokia 6680 125$Nokia 6681 120$Nokia 6101 110$Zenith P42W22B 42 Inch Plasma TV Blowout $700Gateway 42″ Plasma TV 16 : 9 Aspect Ratio, Supports1280 $800Samsung HP-R4252 Plasma TV & Monitors $900Samsung HP-R5052 50″ Plasma TV $1,500Panasonic TH-37PWD8UK Plasma TV $650Gateway 42″ Plasma TV 16 : 9 Aspect Ratio, Supports 1280 $700Sony Wega Ke-42M1 42-Inch EDTV Plasma TV $800Panasonic TH-42PWD8UK Plasma TV & Monitors $650Gateway 50″ HD Plasma TV 16 : 9 Aspect Ratio $1,500Panasonic TH-42PWD8UK 42″ Plasma TV – Exceptional 4000:1 $700Panasonic TH-42PD50U 42″ Diagonal Plasma TV Special Order $750Samsung HPR5052 50 High Definition Plasma TV with $1,100Panasonic TH-42PWD8UK Plasma TV $800Philips 42 Inch Plasma TV and Monitor 42PF9630A $1,050Sony VAIO V505DC2 Series Notebook Intel Pentium4-M 2.2 $800Sony VAIO PCG-V505AC Notebook Computer Intel Pentium 4 M $700New Sony VAIO PCG-V505DC21 P4 2.2ghz Laptop Notebook PC $700Sony VAIO VGN-U70 Notebook Computer – World’S Smallest $1,000Dell Latitude Laptop $300Dell Latitude D800 15″ Notebook/Laptop Computer PC $1,200Dell XPS M170 2GHZ 1GB 80GB 256M 7800GTX Laptop Computer $1,150Dell Laptop M60-HQCP741 $750Dell Laptop M60-JJ50G51 $650DEC640 – Dell Latitude C640 Notebook/Laptop Computer $400IBM ThinkPad T30 236697U $1,150IBM Thinkpad T23 26475NU $1,050IBM 2379DKU Notebook Computer $535IBM / Lenovo – N100 Intel Centrino Duo Mobile 1.6G $500Hewlett Packard PG402UA#ABA HP Compaq nw8000 Pentium-M $1,530Hewlett Packard DV131U#ABA HP Compaq tr3000,Pentium-III $1,300HP Compaq tc4200,Pentium-M 750 (1.86GHz),12.1 inch XGA $800HP nc6400 Notebook PC $750Hewlett Packard PR127UA#ABA HP Compaq nc6120,Pentium-m $820HP nc6400 Notebook PC $700HP Pavilion HP DV5250us 15.4″ Widescreen Laptop w/1.83 $750Sony VAIO Pentium M 1.6GHz Centrino Wireless B+G $650Sony VAIO VAIO SZ140P10 Notebook $1,050Sony VAIO VGN-A690 17 Notebook PC $530Sony VAIO Pentium M 2.26GHz Notebook PC (Open Box) $900Sony VAIO S170 Intel Pentium M 1.5GHz, 13.3in WXGA, 40GB $800(allphonesltd1999@hotmail.com)(allphonesltd1@yahoo.co.uk)
The whole idea sounds like a good idea to me. Thanks for sharing.