
 An article in yesterday’s NYT says we’re producing digital information in volumes that will soon exceed our capacity to store it. Something about these huge numbers didn’t ring right. “Where is the knowledge we have lost in information?”, TS Eliot once wrote. Do we have the capacity to actually use all this digital exhaust? Is it all worth producing, and is the ease of producing and storing it just making it harder to find the stuff that’s actually useful? And for all the zeroes after these numbers, is this really a lot of information for nearly seven billion humans to be producing? I decided to do some math to find out. Since we’re speaking in large round numbers, there are about 5 x 1030 bacteria on Earth. Even if these remarkably complex creatures only produced one byte of information each in their lifetimes, their total information production would be 30 billion times the aggregate human output of a mere 161 exabytes. So by comparison with bacteria, we humans are still junior league information producers. Our bodies are also pretty good information processors compared to computers. A recent study claimed that our bodies process 2MB of information per second (most of it unconscious or subconscious) or 5 x 1015 bytes of information in a lifetime. So all human bodies currently on the planet process 5 x 1023 bytes of non-digital information each year, or about 2500 times as much as the digital information which we are collectively producing and which all our machines are collectively processing, storing and distributing. But then our machines are pretty dumb and slow compared to the marvel of the human body. Even more remarkable, the conscious human mind is only able to absorb an average of 3 bytes of information per second over a lifetime, or 7GB of information in an entire lifetime. That means the 6.7 billion humans brains on the planet are only able to absorb 6 x 1017 bytes of information in a year, of which at least 95% is sensory or interpersonal (i.e. non-digital), so collectively we are absorbing only 3 x 1016 bytes of digital information in a year, increasing by our population growth rate of about 2%/year. Meanwhile the amount of digital information we are producing (presumably in the hope others will somehow use it) is currently (according to the NYT article) 161 exabytes or 2 x 1020 bytes of information per year, growing at over 50% per year. So we are already producing 6000 times as much digital information as we’re consuming (1500 times as much if you exclude duplicates/copies of information), and by 2010 we’ll be producing 30,000 times as much digital information as we consume (7000 times as much if you exclude duplicates/copies). That means at least 1499/1500 (99.93%) of the digital information being produced by us and our machines will never be read or consumed or otherwise used by any human. We are producing and capturing it “just in case”. And an increasing amount of the digital information we produce is designed to be read andused only by other machines. Just as well I guess. My head’s already full. Thanks to my colleague Gabrielle Gaedecke for the link. Graphic from michaelgibbs.com. Category: Technology & Society
|
Navigation
Collapsniks
Albert Bates (US)
Andrew Nikiforuk (CA)
Brutus (US)
Carolyn Baker (US)*
Catherine Ingram (US)
Chris Hedges (US)
Dahr Jamail (US)
Dean Spillane-Walker (US)*
Derrick Jensen (US)
Dougald & Paul (IE/SE)*
Erik Michaels (US)
Gail Tverberg (US)
Guy McPherson (US)
Honest Sorcerer
Janaia & Robin (US)*
Jem Bendell (UK)
Mari Werner
Michael Dowd (US)*
Nate Hagens (US)
Paul Heft (US)*
Post Carbon Inst. (US)
Resilience (US)
Richard Heinberg (US)
Robert Jensen (US)
Roy Scranton (US)
Sam Mitchell (US)
Tim Morgan (UK)
Tim Watkins (UK)
Umair Haque (UK)
William Rees (CA)
XrayMike (AU)
Radical Non-Duality
Tony Parsons
Jim Newman
Tim Cliss
Andreas Müller
Kenneth Madden
Emerson Lim
Nancy Neithercut
Rosemarijn Roes
Frank McCaughey
Clare Cherikoff
Ere Parek, Izzy Cloke, Zabi AmaniEssential Reading
Archive by Category
My Bio, Contact Info, Signature Posts
About the Author (2023)
My Circles
E-mail me
--- My Best 200 Posts, 2003-22 by category, from newest to oldest ---
Collapse Watch:
Hope — On the Balance of Probabilities
The Caste War for the Dregs
Recuperation, Accommodation, Resilience
How Do We Teach the Critical Skills
Collapse Not Apocalypse
Effective Activism
'Making Sense of the World' Reading List
Notes From the Rising Dark
What is Exponential Decay
Collapse: Slowly Then Suddenly
Slouching Towards Bethlehem
Making Sense of Who We Are
What Would Net-Zero Emissions Look Like?
Post Collapse with Michael Dowd (video)
Why Economic Collapse Will Precede Climate Collapse
Being Adaptable: A Reminder List
A Culture of Fear
What Will It Take?
A Future Without Us
Dean Walker Interview (video)
The Mushroom at the End of the World
What Would It Take To Live Sustainably?
The New Political Map (Poster)
Beyond Belief
Complexity and Collapse
Requiem for a Species
Civilization Disease
What a Desolated Earth Looks Like
If We Had a Better Story...
Giving Up on Environmentalism
The Hard Part is Finding People Who Care
Going Vegan
The Dark & Gathering Sameness of the World
The End of Philosophy
A Short History of Progress
The Boiling Frog
Our Culture / Ourselves:
A CoVid-19 Recap
What It Means to be Human
A Culture Built on Wrong Models
Understanding Conservatives
Our Unique Capacity for Hatred
Not Meant to Govern Each Other
The Humanist Trap
Credulous
Amazing What People Get Used To
My Reluctant Misanthropy
The Dawn of Everything
Species Shame
Why Misinformation Doesn't Work
The Lab-Leak Hypothesis
The Right to Die
CoVid-19: Go for Zero
Pollard's Laws
On Caste
The Process of Self-Organization
The Tragic Spread of Misinformation
A Better Way to Work
The Needs of the Moment
Ask Yourself This
What to Believe Now?
Rogue Primate
Conversation & Silence
The Language of Our Eyes
True Story
May I Ask a Question?
Cultural Acedia: When We Can No Longer Care
Useless Advice
Several Short Sentences About Learning
Why I Don't Want to Hear Your Story
A Harvest of Myths
The Qualities of a Great Story
The Trouble With Stories
A Model of Identity & Community
Not Ready to Do What's Needed
A Culture of Dependence
So What's Next
Ten Things to Do When You're Feeling Hopeless
No Use to the World Broken
Living in Another World
Does Language Restrict What We Can Think?
The Value of Conversation Manifesto Nobody Knows Anything
If I Only Had 37 Days
The Only Life We Know
A Long Way Down
No Noble Savages
Figments of Reality
Too Far Ahead
Learning From Nature
The Rogue Animal
How the World Really Works:
Making Sense of Scents
An Age of Wonder
The Truth About Ukraine
Navigating Complexity
The Supply Chain Problem
The Promise of Dialogue
Too Dumb to Take Care of Ourselves
Extinction Capitalism
Homeless
Republicans Slide Into Fascism
All the Things I Was Wrong About
Several Short Sentences About Sharks
How Change Happens
What's the Best Possible Outcome?
The Perpetual Growth Machine
We Make Zero
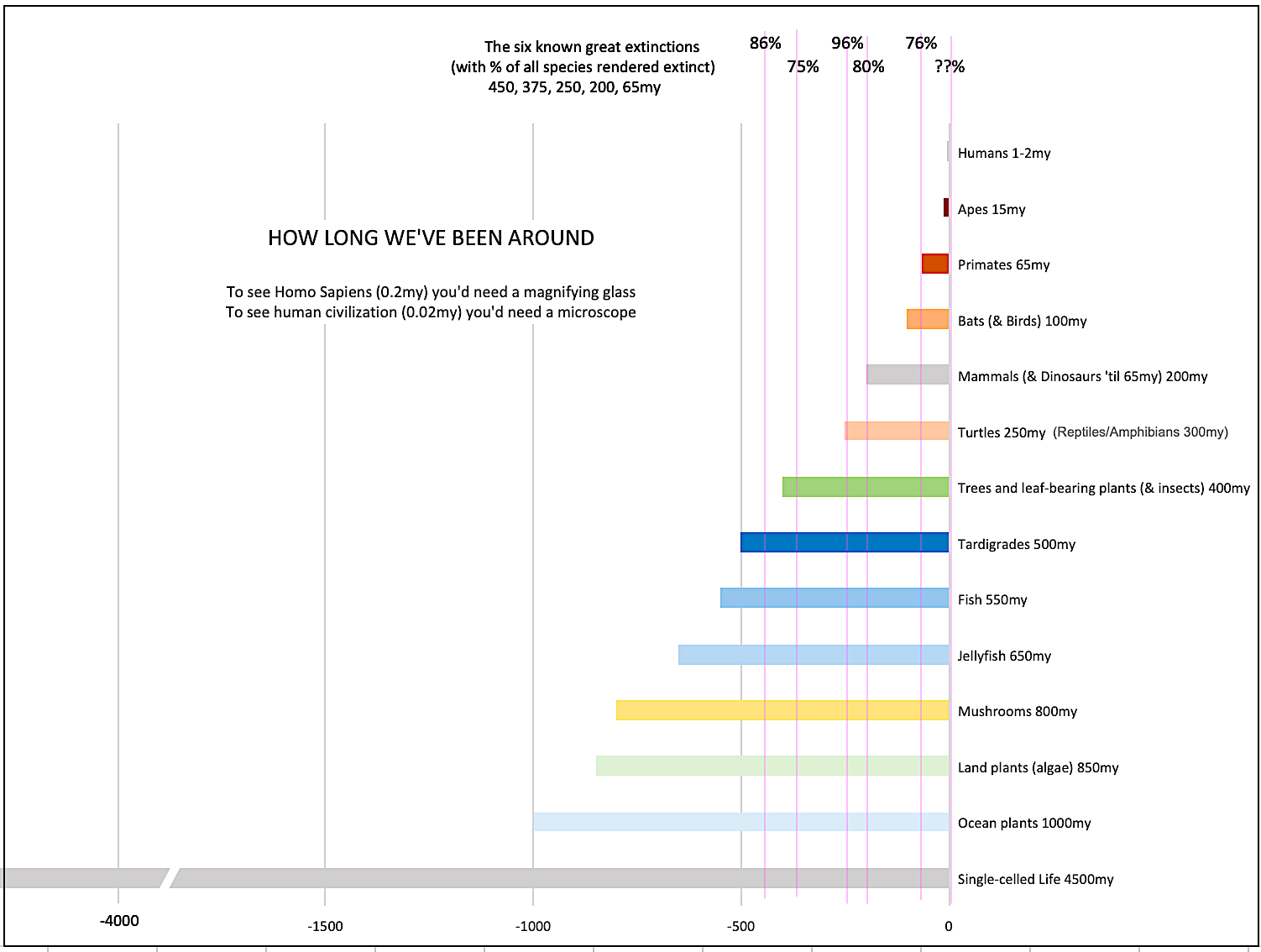
How Long We've Been Around (graphic)
If You Wanted to Sabotage the Elections
Collective Intelligence & Complexity
Ten Things I Wish I'd Learned Earlier
The Problem With Systems
Against Hope (Video)
The Admission of Necessary Ignorance
Several Short Sentences About Jellyfish
Loren Eiseley, in Verse
A Synopsis of 'Finding the Sweet Spot'
Learning from Indigenous Cultures
The Gift Economy
The Job of the Media
The Wal-Mart Dilemma
The Illusion of the Separate Self, and Free Will:
No Free Will, No Freedom
The Other Side of 'No Me'
This Body Takes Me For a Walk
The Only One Who Really Knew Me
No Free Will — Fightin' Words
The Paradox of the Self
A Radical Non-Duality FAQ
What We Think We Know
Bark Bark Bark Bark Bark Bark Bark
Healing From Ourselves
The Entanglement Hypothesis
Nothing Needs to Happen
Nothing to Say About This
What I Wanted to Believe
A Continuous Reassemblage of Meaning
No Choice But to Misbehave
What's Apparently Happening
A Different Kind of Animal
Happy Now?
This Creature
Did Early Humans Have Selves?
Nothing On Offer Here
Even Simpler and More Hopeless Than That
Glimpses
How Our Bodies Sense the World
Fragments
What Happens in Vagus
We Have No Choice
Never Comfortable in the Skin of Self
Letting Go of the Story of Me
All There Is, Is This
A Theory of No Mind
Creative Works:
Mindful Wanderings (Reflections) (Archive)
A Prayer to No One
Frogs' Hollow (Short Story)
We Do What We Do (Poem)
Negative Assertions (Poem)
Reminder (Short Story)
A Canadian Sorry (Satire)
Under No Illusions (Short Story)
The Ever-Stranger (Poem)
The Fortune Teller (Short Story)
Non-Duality Dude (Play)
Your Self: An Owner's Manual (Satire)
All the Things I Thought I Knew (Short Story)
On the Shoulders of Giants (Short Story)
Improv (Poem)
Calling the Cage Freedom (Short Story)
Rune (Poem)
Only This (Poem)
The Other Extinction (Short Story)
Invisible (Poem)
Disruption (Short Story)
A Thought-Less Experiment (Poem)
Speaking Grosbeak (Short Story)
The Only Way There (Short Story)
The Wild Man (Short Story)
Flywheel (Short Story)
The Opposite of Presence (Satire)
How to Make Love Last (Poem)
The Horses' Bodies (Poem)
Enough (Lament)
Distracted (Short Story)
Worse, Still (Poem)
Conjurer (Satire)
A Conversation (Short Story)
Farewell to Albion (Poem)
My Other Sites




{kind=link}
{kind=link}
yeah …
“…our bodies process 2MB of information per second” yet “…the conscious human mind is only able to absorb an average of 3 bytes of information per second”. May be that data is correct because that ratio makes no sense to me. Even more confusing to me is how they could make these measurements since our bodys are not binary devices. I have no background in this area but I do not believe that 3 bytes/second can possibly be correct.
Indeed – 3 bytes/second seems ridiculously low. If you compress,say, a piece of music until it starts drastically losing quality, you’re still hearing tens of thousands of bytes worth of audio data per second. Granted, you aren’t extracting every possible bit of data from the music, but you’re hearing the music, and the lyrics, and noticing the nature and quality of the distortion and artifacts. And you may be managing ten or twelve chat conversations at once on your computer, while talking aloud to your partner, noticing what you feel as you stretch your neck and back, solving some business problem in your head, and smelling that the back door is open, the brownies in the oven are nearly done, and your dog is sneaking up behind you.Myself, I’ve been a speed-reader all my life, and from personal experience I basically agree with the theory of speed-reading I came across later in life, that suggests we can take in about seven CHUNKS of information per second, and the secret to reading faster with full comprehension is to take in LARGER chunks at once, rather than trying to take them in faster.Anyone who works professionally with images can compare the size of file needed to accurately contain images without compression with the amount of information a professional can take in from an image in a single glance – likewise anyone who spends significant time outdoors and evaluates their environment as a whole. Sure, you can fool people with compression, basically by getting them to make *assumptions* about what they see. But getting them to settle for less data is not the same as not being able to take it in.The three bytes/second MAY be accurate if the definition is “how much random meaningless data, presented in a sensory-unfriendly format, can a person perfectly memorize?” i.e. strings of random digits.Another counterexample – compare the “compare two pictures and find the differences” puzzles with the real-life experience of walking into a personallyimportant room and noticing instantly that something is awry. How much data does it take to scan a whole room and notice the scissors aren’t where you left them?