
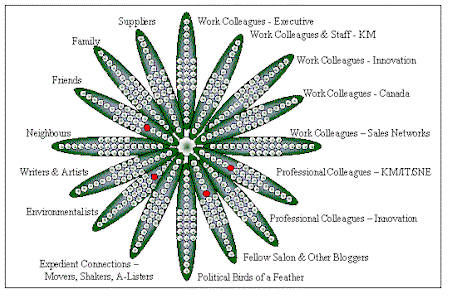
 I‘ve written recently about the future state of business, a world incorporating powerful, versatile social networking tools. And I’ve played with most of the first-generation social software and read volumes about how it will, or won’t, work in business and ultimately affect our daily lives. The concept is wonderful, and the technology is fun, but the tools developed so far suffer from three fatal flaws:
In this month’s Darwin Magazine, social networking guru Stowe Boyd also laments the growing pains of many of the first-generation tools, and the absurdly high and premature expectations that people have of them. “My bet is that social networking services will resist standardization until they see the benefits of converging all sorts of private and public network information, and realize that no one company can create and manage all of it”, he says. The heterogeneity of both content and context is producing specialized social tools that are excellent for certain focused purposes, but useless for others, and an aggregation of content — filled-in forms, esoteric discussion threads and context-free ‘knowledge objects’ — that is cumbersome and largely unreusable. In an earlier post I stressed the importance of allowing each individual to maintain and organize their own content and their own networks their own way. At that time I said: “When you force people to adapt their mental models to a standard model (inevitably a complex one to accommodate a variety of specifications), a standard model that is dictated by the technology and its designers, you will get no usage, or at best reluctant, inefficient usage.” If I were start all over again, to design the second generation of social software, it would be transparent to the user, wouldn’t require any submissions, wouldn’t keep any content in any central location, and would be so simple to use that even people without computers would use it. The next floor of the house is the metadata. Software developers would work with the users of individuals’ content other than the individual him/herself to ascertain how they might want to use the individual’s newly-ordered content, and develop tools to harvest the relevant metadata to do that. This second layer of tools essentially reorganizes the individual’s content, transparently, in ways that make it more useful to the individual’s networks — actual and potential friends, associates, customers, suppliers etc. These tools would spider the content and essentially ‘fill in the forms’ that those in each of the individual’s networks might need to access the individual’s information in the format they want it in. The PCM tools would allow people to specify which content could be seen and accessed by others with the appropriate ‘permissions’, and the metadata tools would repect these permissions. These metadata tools would be invisible to the individual user, and would work automatically in the background as the individual added, deleted, and changed the content using the PCM tools. Still with me? Now comes the piËce de rÈsistance. The third level of the house is the networking and connectivity tools, the ones that, analogous to the telephone switch, actually enable the identification of relationships, the making of connections, the transfer of information, and ultimately even collaboration and other more dynamic interactive applications of connectivity — transactions. These applications harvest and mine the metadata, and have no content of their own. They operate on a just-in-time basis. These tools might include an Expertise Finder, a Connector, a Super Address Book, a Network Builder, a Publisher, and a Subscriber. So for example, if I’m researching solar power for my new house, or looking for people to work with me on a Meeting of Minds business assignment, I could use the Expertise Finder tool to identify who I could and should talk to, what information each of those experts has in their personal content that is permissioned for me to look at, multiple contact information for each of those experts, and the cost, if any, of contacting the expert and/or accessing their personal content. A Connector tool would then enable one-click connection to the selected expert(s) regardless of medium selected — telephony, instant or asynchronous messaging, Simple Virtual Presence, etc. The Connector tool, just like a telephone switch, would connect people within an organization, or between organizations, or between an individual and someone in an organization — it wouldn’t matter. So if I work for a bank and I need to find an expert in financial derivatives, it would work exactly as my personal solar power search did. I could then choose between ‘found experts’ within the bank and those outside. If I want to contact my father in Winnipeg, or the group I play poker with on Friday nights, I would use the Super Address Book instead of the Expertise Finder before using the Connector tool, but the process would be analogous and as simple and intuitive as looking in a rolodex or phone book. And if I wanted to build a new network of people interested in discussing New Collaborative Enterprises, or whether Kerry should pick Kucinich as a running mate, I might use the Network Builder tool, which would function exactly like the Expertise Finder except it would identify people with particular interests rather than particular expertise. Finally, I could use the Publisher tool to ‘push’ selected content out instead of waiting for people to come and get it, and a Subscriber tool, based on RSS, that puts out a ‘standing order’ to pull in and aggregate others’ content that meets my specified criteria. Just-in-time. Dead simple. Built on information I maintain, control and organize my way. Personal versus business information, internal or external, doesn’t matter. A utility. An appliance. You could even build additional commercial and transaction tools on top of this. Buy a ‘smart’ fridge/freezer that takes inventory of what you have, ‘permission’ it to feed your PCM tool, and your grocery supplier can automatically compute, fill and deliver your order with no intervention by you at all. There are some important lessons to learn from the success and failure of previous technologies. A combination of simplicity-of-use, personalizability and adaptability has made tools like paper, books, pencils, paints, diaries, typewriters, newspapers, timepieces, telephones, radio & TV, personal calculators, CDs and DVDs ubiquitous and hugely popular. In contrast, the lack of these attributes in tools like the PC, musical instruments, the VCR, the fax machine, almost all software, PDAs and videoconferencing, has severely limited the market for these tools, and caused millions to curse their complexity. I don’t blame first-generation social software designers for making the three mistakes that already have detractors raising their eyebrows. We need to do lots of experiments to see what will work and what won’t. There’s no harm designing and playing with skylights and new types of shingles even before the foundation is ready to be poured. And as Stowe said, social software “will become the cornerstone of a revolution in IT”, not to mention a revolution in how we connect, network, and organize and share information — activities that comprise much of the fabric of our lives. We just need to remember: Simple, Personal, Decentralized, Just-in-time. |
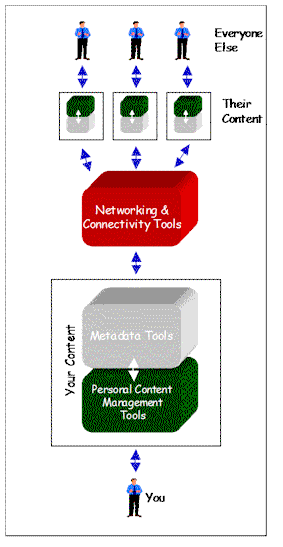 That may sound like a tall order, but it really isn’t. It would be like building a house. Let’s start with content, the foundation of the house. Rather than getting people to submit stuff, we need to help people to organize the personal information they already have, and then harvest it automatically. When I talk to people in the front lines of just about every business, from proprietorships to large companies, they confess their filing cabinets, the document folders on their hard drives, rolodexes and other personal collections of information are chaotic and impossible to find things in. They also say no one ever taught them how to organize these personal repositories so that content could be found easily. Everyone just assumed that the skill to do this comes naturally. So first order of business is
That may sound like a tall order, but it really isn’t. It would be like building a house. Let’s start with content, the foundation of the house. Rather than getting people to submit stuff, we need to help people to organize the personal information they already have, and then harvest it automatically. When I talk to people in the front lines of just about every business, from proprietorships to large companies, they confess their filing cabinets, the document folders on their hard drives, rolodexes and other personal collections of information are chaotic and impossible to find things in. They also say no one ever taught them how to organize these personal repositories so that content could be found easily. Everyone just assumed that the skill to do this comes naturally. So first order of business is Navigation
Collapsniks
Albert Bates (US)
Andrew Nikiforuk (CA)
Brutus (US)
Carolyn Baker (US)*
Catherine Ingram (US)
Chris Hedges (US)
Dahr Jamail (US)
Dean Spillane-Walker (US)*
Derrick Jensen (US)
Dougald & Paul (IE/SE)*
Erik Michaels (US)
Gail Tverberg (US)
Guy McPherson (US)
Honest Sorcerer
Janaia & Robin (US)*
Jem Bendell (UK)
Mari Werner
Michael Dowd (US)*
Nate Hagens (US)
Paul Heft (US)*
Post Carbon Inst. (US)
Resilience (US)
Richard Heinberg (US)
Robert Jensen (US)
Roy Scranton (US)
Sam Mitchell (US)
Tim Morgan (UK)
Tim Watkins (UK)
Umair Haque (UK)
William Rees (CA)
XrayMike (AU)
Radical Non-Duality
Tony Parsons
Jim Newman
Tim Cliss
Andreas Müller
Kenneth Madden
Emerson Lim
Nancy Neithercut
Rosemarijn Roes
Frank McCaughey
Clare Cherikoff
Ere Parek, Izzy Cloke, Zabi AmaniEssential Reading
Archive by Category
My Bio, Contact Info, Signature Posts
About the Author (2023)
My Circles
E-mail me
--- My Best 200 Posts, 2003-22 by category, from newest to oldest ---
Collapse Watch:
Hope — On the Balance of Probabilities
The Caste War for the Dregs
Recuperation, Accommodation, Resilience
How Do We Teach the Critical Skills
Collapse Not Apocalypse
Effective Activism
'Making Sense of the World' Reading List
Notes From the Rising Dark
What is Exponential Decay
Collapse: Slowly Then Suddenly
Slouching Towards Bethlehem
Making Sense of Who We Are
What Would Net-Zero Emissions Look Like?
Post Collapse with Michael Dowd (video)
Why Economic Collapse Will Precede Climate Collapse
Being Adaptable: A Reminder List
A Culture of Fear
What Will It Take?
A Future Without Us
Dean Walker Interview (video)
The Mushroom at the End of the World
What Would It Take To Live Sustainably?
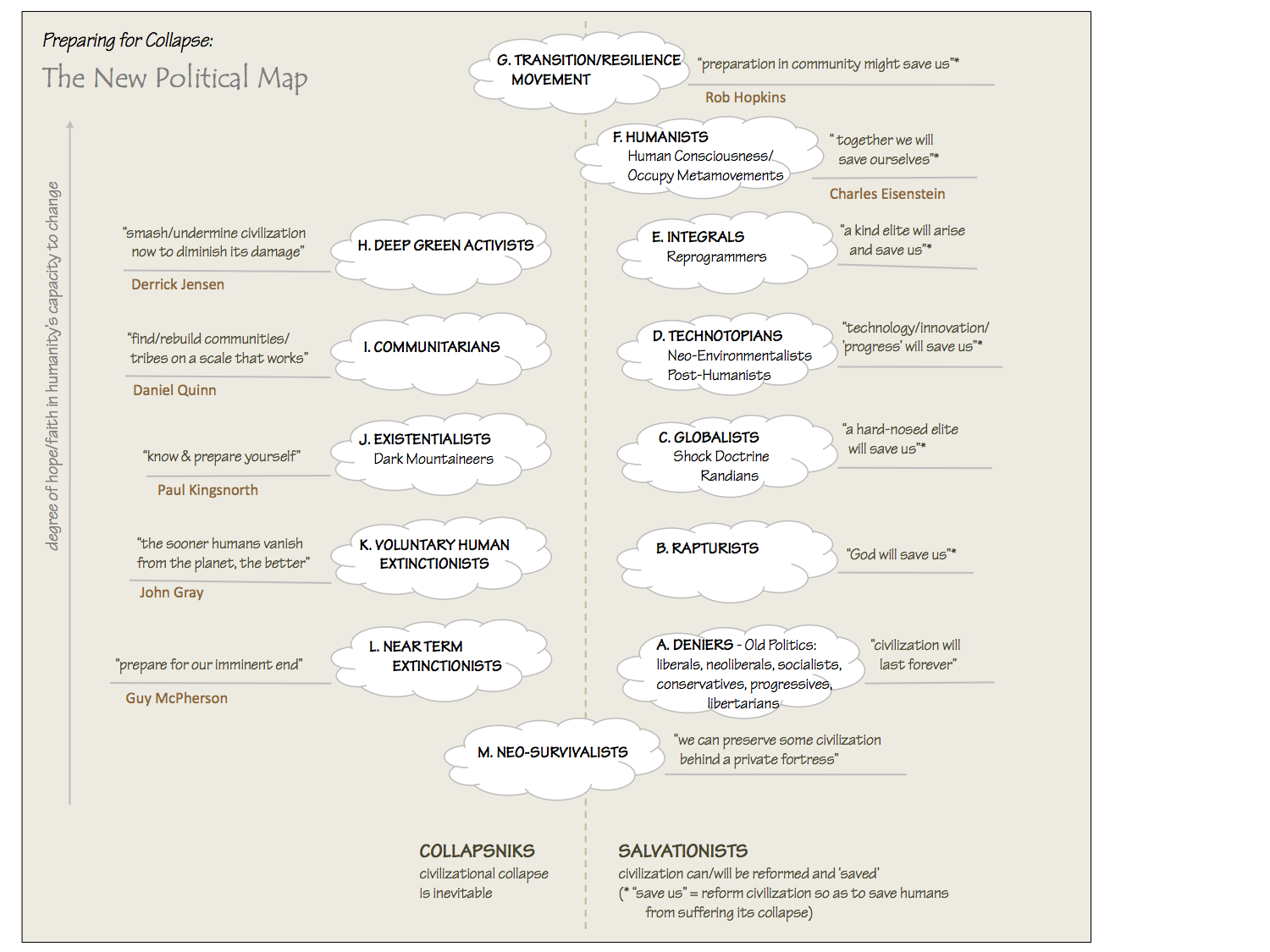
The New Political Map (Poster)
Beyond Belief
Complexity and Collapse
Requiem for a Species
Civilization Disease
What a Desolated Earth Looks Like
If We Had a Better Story...
Giving Up on Environmentalism
The Hard Part is Finding People Who Care
Going Vegan
The Dark & Gathering Sameness of the World
The End of Philosophy
A Short History of Progress
The Boiling Frog
Our Culture / Ourselves:
A CoVid-19 Recap
What It Means to be Human
A Culture Built on Wrong Models
Understanding Conservatives
Our Unique Capacity for Hatred
Not Meant to Govern Each Other
The Humanist Trap
Credulous
Amazing What People Get Used To
My Reluctant Misanthropy
The Dawn of Everything
Species Shame
Why Misinformation Doesn't Work
The Lab-Leak Hypothesis
The Right to Die
CoVid-19: Go for Zero
Pollard's Laws
On Caste
The Process of Self-Organization
The Tragic Spread of Misinformation
A Better Way to Work
The Needs of the Moment
Ask Yourself This
What to Believe Now?
Rogue Primate
Conversation & Silence
The Language of Our Eyes
True Story
May I Ask a Question?
Cultural Acedia: When We Can No Longer Care
Useless Advice
Several Short Sentences About Learning
Why I Don't Want to Hear Your Story
A Harvest of Myths
The Qualities of a Great Story
The Trouble With Stories
A Model of Identity & Community
Not Ready to Do What's Needed
A Culture of Dependence
So What's Next
Ten Things to Do When You're Feeling Hopeless
No Use to the World Broken
Living in Another World
Does Language Restrict What We Can Think?
The Value of Conversation Manifesto Nobody Knows Anything
If I Only Had 37 Days
The Only Life We Know
A Long Way Down
No Noble Savages
Figments of Reality
Too Far Ahead
Learning From Nature
The Rogue Animal
How the World Really Works:
Making Sense of Scents
An Age of Wonder
The Truth About Ukraine
Navigating Complexity
The Supply Chain Problem
The Promise of Dialogue
Too Dumb to Take Care of Ourselves
Extinction Capitalism
Homeless
Republicans Slide Into Fascism
All the Things I Was Wrong About
Several Short Sentences About Sharks
How Change Happens
What's the Best Possible Outcome?
The Perpetual Growth Machine
We Make Zero
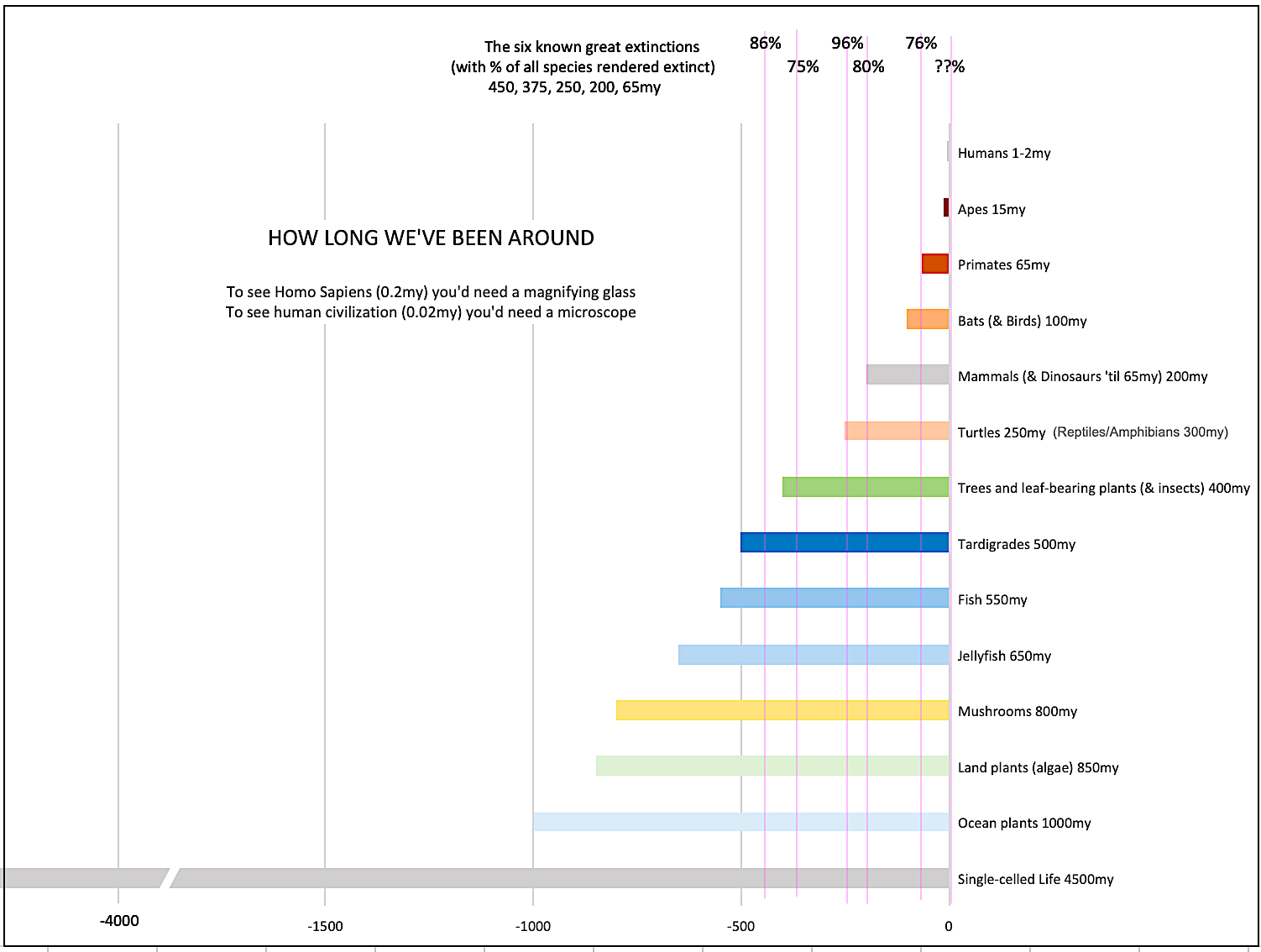
How Long We've Been Around (graphic)
If You Wanted to Sabotage the Elections
Collective Intelligence & Complexity
Ten Things I Wish I'd Learned Earlier
The Problem With Systems
Against Hope (Video)
The Admission of Necessary Ignorance
Several Short Sentences About Jellyfish
Loren Eiseley, in Verse
A Synopsis of 'Finding the Sweet Spot'
Learning from Indigenous Cultures
The Gift Economy
The Job of the Media
The Wal-Mart Dilemma
The Illusion of the Separate Self, and Free Will:
No Free Will, No Freedom
The Other Side of 'No Me'
This Body Takes Me For a Walk
The Only One Who Really Knew Me
No Free Will — Fightin' Words
The Paradox of the Self
A Radical Non-Duality FAQ
What We Think We Know
Bark Bark Bark Bark Bark Bark Bark
Healing From Ourselves
The Entanglement Hypothesis
Nothing Needs to Happen
Nothing to Say About This
What I Wanted to Believe
A Continuous Reassemblage of Meaning
No Choice But to Misbehave
What's Apparently Happening
A Different Kind of Animal
Happy Now?
This Creature
Did Early Humans Have Selves?
Nothing On Offer Here
Even Simpler and More Hopeless Than That
Glimpses
How Our Bodies Sense the World
Fragments
What Happens in Vagus
We Have No Choice
Never Comfortable in the Skin of Self
Letting Go of the Story of Me
All There Is, Is This
A Theory of No Mind
Creative Works:
Mindful Wanderings (Reflections) (Archive)
A Prayer to No One
Frogs' Hollow (Short Story)
We Do What We Do (Poem)
Negative Assertions (Poem)
Reminder (Short Story)
A Canadian Sorry (Satire)
Under No Illusions (Short Story)
The Ever-Stranger (Poem)
The Fortune Teller (Short Story)
Non-Duality Dude (Play)
Your Self: An Owner's Manual (Satire)
All the Things I Thought I Knew (Short Story)
On the Shoulders of Giants (Short Story)
Improv (Poem)
Calling the Cage Freedom (Short Story)
Rune (Poem)
Only This (Poem)
The Other Extinction (Short Story)
Invisible (Poem)
Disruption (Short Story)
A Thought-Less Experiment (Poem)
Speaking Grosbeak (Short Story)
The Only Way There (Short Story)
The Wild Man (Short Story)
Flywheel (Short Story)
The Opposite of Presence (Satire)
How to Make Love Last (Poem)
The Horses' Bodies (Poem)
Enough (Lament)
Distracted (Short Story)
Worse, Still (Poem)
Conjurer (Satire)
A Conversation (Short Story)
Farewell to Albion (Poem)
My Other Sites




{kind=link}
{kind=link}
Thanks – starting just now to start thinking about the connection between Simple, Personal, Decentralized and Just-in-Time and the principles of Game Theory built into Massively-Multiplayer Online Games. I wrote a bit of a bleat on it yesterday and posted it on blog today, as I started thinking a few days ago about how overengineered the SNS I’ve seen to date is (as you pointed out). Everyone wants it to work magic without investing much of themselves in it – they want to reach out and touch someone, and have the app do the work of building a real relationship for them, somehow.Good games are often Simple at the “interface” level, complexity behind the eyes as it were, Personal because you’re you playing it and getting whatever juice you get out of it (the passion only you know for it – different than spectating), Decentralized by virtue of the participant(s) being central to the game of themselves, and of course Real-Time.We’ve never played the Game of Life on line before. We need to “play” with social software to find out what the design parameters need to be, not decide what they are before we build the apps.
Jon: Thanks. You make a good point about my use of the term ‘simple’. I should have said ‘simple to use’. There’s no question what’s going on behind the scenes and invisible to the user is quite sophisticated.
Very well put Dave. We have always held the notion that SNA needs to be transparent to the user and (borrowing from Ross Mayfield) adapt to the user’s environment. Its hard to make SNA the center-piece without turning it into an artificial process. In WiredReach , we took our initial stab at “Personal Content Management” with a simple address book interface that helps organize one’s rolodex (and keep it current). There needs to be continous learning and evolution to extend this to other types of data. Keeping the architecture decentralized and rooted in standards allows for such experimentation…
Hi Dave,I just wanted to point a tool out to you that you may not know about, that follows (at least in part) some of the principles you outlined here. It’s a peer-to-peer semantic knowledge sharing network called Human Links:http://www.human-links.com/2/en/index.phpThe software is developed by a small focused French startup called Amoweba that was founded by experienced knowledge management / text mining professionals. (I have nothing to do with them, they are just part of my network.)Looking forward to reading more of your insights and your comments on Human Links :)
You’re expecting the same people who can’t figure out their VCR clocks to be able to share out their personal files and data on their hard drives without getting hacked, or that we could trust the tools that enforce the privileges? That sounds very far-fetched to me!At least I know, with central management of the content, that what’s up there is only what *I* put up there, not what someone else was able to dig out of my own machine…There’s not a snowball’s chance on Vesuvius that I’d ever be confortable with the kind of structure that you describe, especially on a personal machine
Michael: It may not make you feel more comfortable, but the idea is that you would ‘partition’ your hard drive into shareable vs non-shareable content (much the way P2P music sharing does) and you could further restrict certain content to certain people or groups. Could it be hacked? Probably. There’s always going to be some risk. My sense is that the risk of misusing ‘centralized’ content due its lack of context and the lack of consultation (perhaps even lack of awareness) of who authored it and why) is a much greater risk.
P2P by definition (the correct one) is that it’s a collection of client/server connections, i.e. ‘centralized’ content. And the fact that most lack context (or consultation) doesn’t make it more risky than P2P. If you recall, WWW got started because of centralized control and distribution of information and lookup services, taking advantage of available WAN. It could almost be said that eveyone back in the old days were all P2P, i.e. everyone had a server. But as a natural progression, more and more were simply clients. It will continue, as devices diverge from PC to handhelds. To me P2P was just an outcry of folks who couldn’t get good server services from the brain-dead industry. Look at online music now: it’s being service by centralized services.
I’m sure it’s been pointed out at some point, but I see Apple heading towards personal content management in Mac OS. And to reach the level of transparency and ubiquity that’s required for “true” personal content management, a layer or two in the operating system makes sense. Look at iLife in combination with the recently announced Spotlight and Automator. Certainly, it’s primitive in comparison to what you’re describing, but it’s a step in the right direction. And if Apple’s doing it now, I suspect we’ll see the Windows world start catching up (or at least heading in that direction) as early as Longhorn.(I guess this comment is a bit late to the conversation- I’ve been following the blog for a while, but for some reason, yesterday, all of your ideas on knowledge management and existential enterprise really struck home with me. Now I’ve read pretty much everything you’ve written recently on it. Excellent stuff. I only wish I’d had it a year ago.)