
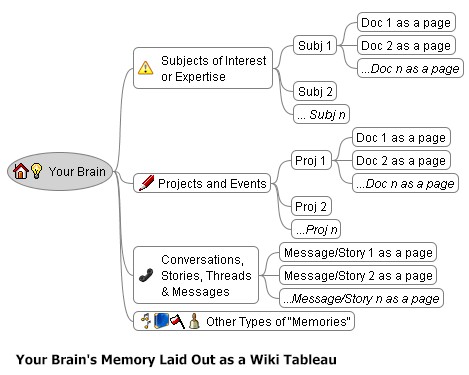
 If it weren’t for Google Desktop I’d be spending an inordinate amount of time looking for stuff I’ve written, and then forgotten what I’d named it. But Google Desktop doesn’t do the whole job — I often comment on others’ blogs, in forums, in wikis and other places that most tools don’t keep track of, and I can never remember where these important thoughts were placed. And with multimedia and collaborative sites becoming more affordable and more important, it’s only going to get worse. I know CoComment is trying to help, but it’s just one more piece to add to the memory storage puzzle, and doesn’t even handle all blogs (including mine). What we need is a web page that works kind of in reverse — keeping track of everything we’ve ‘sent out’, in any online medium, regardless of where it ended up. This was an idea I proposed as CKO a few years ago (it was deemed technically too difficult). At that point all I wanted was for employees who had contributed documents (including e-mail messages) to internal repositories to have a place where all such contributed knowledge could be found in one place, so at annual performance review time it would be easy for them to say: “Here, this is what I contributed to our company’s collective knowledge this year.” The closest analogy I can think of is a scrapbook, a place where we keep all our ‘memories’. The online equivalent I’d like to see would capture all of the following on one ‘page’:
This massive aggregation would comprise ATSYCA (All The Stuff You Care About), a kind of super-memory or ‘subset of the Web’. Almost as important as the content itself is the names and contact information for all its authors and contributors, ATPYCA (All The People You Care About). Our brains seem to have an extraordinary random-access way of storing and finding all this stuff, but as new media are increasing the volume of this content by orders of magnitude (and old age is weakening the effectiveness of its recall), we need to rely more and more on mechanical aids to supplement our mental capacity and information processes. All this information needs to be ‘virtually’ organized in three different ways:
Search engines can enable the second type of use effectively (though with enormous waste, since every single word is indexed). They handle the first and third types of use badly. The first type of use, by subject (personal information taxonomy) needs a graphical layout organized according to the tableau at the top of the page, described in this earlier post, a landscape you could navigate from top level and drill down to as much depth as made sense, to organize all your ATSYCA/ATPYCA. That taxonomy and its granularity could evolve over time — you could ‘redraw the landscape’ as you learned more about some subjects and integrated thinking on others. The third type of use (by context and connection) also needs a graphical format, but this time ‘parsing’ and linking all the content by what (and who) it was connected to, rather than by subject. It would present a ‘route map’ rather than a ‘logical map’ of this content. It might also allow you to drill down from a ‘colloquium’ level to a ‘conversation’ level to a ‘thread’ level of granularity, and would provide ‘departure points’ where you could add and simultaneously share content (by allowing you to ‘publish to’ and others to ‘subscribe to’ new departures and amplifications from any node on the map. The result of both the first and third types of navigation could be (or at least include) what would effectively be ‘collective intelligence’ of a group, but the map would allow you to tweak it to your personal ‘view’, deleting or hiding content you didn’t find valuable and adding personal annotations ‘for your eyes only’. Although these taxonomic maps and routing maps (and perhaps tag clouds — you know those things that show the prevalence of tags on a particular site by the size of the font of the tag name) might actually reside on a single web site, or your own hard drive, they could just as easily reside out in hyperspace, where you and others could access them anytime from anywhere, and where they’d be easy to update and maintain. There are some technical challenges to doing this (notably keeping ‘public’ web-hosted and ‘private’ hard drive-located content separate according to each user’s personal permissioning rules), but the biggest challenges are likely to be imaginative: keeping the navigation ‘Google simple’, automating the update of the maps, and enabling interactivity of shared, published and subscribed content. But it shouldn’t be that hard to create such an application. If we don’t get a simple tool that can do this soon, we may literally start losing our minds. |
Navigation
Collapsniks
Albert Bates (US)
Andrew Nikiforuk (CA)
Brutus (US)
Carolyn Baker (US)*
Catherine Ingram (US)
Chris Hedges (US)
Dahr Jamail (US)
Dean Spillane-Walker (US)*
Derrick Jensen (US)
Dougald & Paul (IE/SE)*
Erik Michaels (US)
Gail Tverberg (US)
Guy McPherson (US)
Honest Sorcerer
Janaia & Robin (US)*
Jem Bendell (UK)
Mari Werner
Michael Dowd (US)*
Nate Hagens (US)
Paul Heft (US)*
Post Carbon Inst. (US)
Resilience (US)
Richard Heinberg (US)
Robert Jensen (US)
Roy Scranton (US)
Sam Mitchell (US)
Tim Morgan (UK)
Tim Watkins (UK)
Umair Haque (UK)
William Rees (CA)
XrayMike (AU)
Radical Non-Duality
Tony Parsons
Jim Newman
Tim Cliss
Andreas Müller
Kenneth Madden
Emerson Lim
Nancy Neithercut
Rosemarijn Roes
Frank McCaughey
Clare Cherikoff
Ere Parek, Izzy Cloke, Zabi AmaniEssential Reading
Archive by Category
My Bio, Contact Info, Signature Posts
About the Author (2023)
My Circles
E-mail me
--- My Best 200 Posts, 2003-22 by category, from newest to oldest ---
Collapse Watch:
Hope — On the Balance of Probabilities
The Caste War for the Dregs
Recuperation, Accommodation, Resilience
How Do We Teach the Critical Skills
Collapse Not Apocalypse
Effective Activism
'Making Sense of the World' Reading List
Notes From the Rising Dark
What is Exponential Decay
Collapse: Slowly Then Suddenly
Slouching Towards Bethlehem
Making Sense of Who We Are
What Would Net-Zero Emissions Look Like?
Post Collapse with Michael Dowd (video)
Why Economic Collapse Will Precede Climate Collapse
Being Adaptable: A Reminder List
A Culture of Fear
What Will It Take?
A Future Without Us
Dean Walker Interview (video)
The Mushroom at the End of the World
What Would It Take To Live Sustainably?
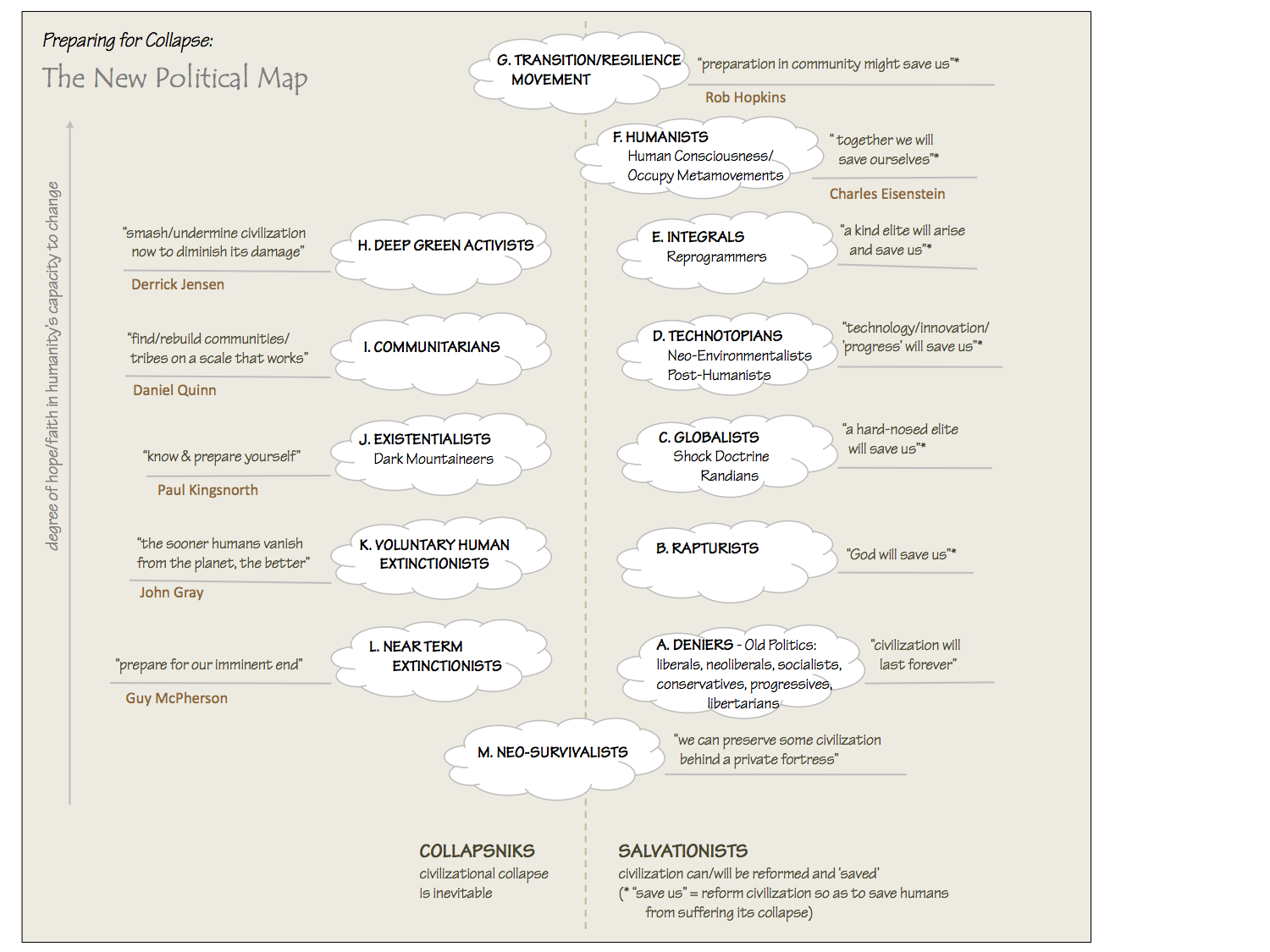
The New Political Map (Poster)
Beyond Belief
Complexity and Collapse
Requiem for a Species
Civilization Disease
What a Desolated Earth Looks Like
If We Had a Better Story...
Giving Up on Environmentalism
The Hard Part is Finding People Who Care
Going Vegan
The Dark & Gathering Sameness of the World
The End of Philosophy
A Short History of Progress
The Boiling Frog
Our Culture / Ourselves:
A CoVid-19 Recap
What It Means to be Human
A Culture Built on Wrong Models
Understanding Conservatives
Our Unique Capacity for Hatred
Not Meant to Govern Each Other
The Humanist Trap
Credulous
Amazing What People Get Used To
My Reluctant Misanthropy
The Dawn of Everything
Species Shame
Why Misinformation Doesn't Work
The Lab-Leak Hypothesis
The Right to Die
CoVid-19: Go for Zero
Pollard's Laws
On Caste
The Process of Self-Organization
The Tragic Spread of Misinformation
A Better Way to Work
The Needs of the Moment
Ask Yourself This
What to Believe Now?
Rogue Primate
Conversation & Silence
The Language of Our Eyes
True Story
May I Ask a Question?
Cultural Acedia: When We Can No Longer Care
Useless Advice
Several Short Sentences About Learning
Why I Don't Want to Hear Your Story
A Harvest of Myths
The Qualities of a Great Story
The Trouble With Stories
A Model of Identity & Community
Not Ready to Do What's Needed
A Culture of Dependence
So What's Next
Ten Things to Do When You're Feeling Hopeless
No Use to the World Broken
Living in Another World
Does Language Restrict What We Can Think?
The Value of Conversation Manifesto Nobody Knows Anything
If I Only Had 37 Days
The Only Life We Know
A Long Way Down
No Noble Savages
Figments of Reality
Too Far Ahead
Learning From Nature
The Rogue Animal
How the World Really Works:
Making Sense of Scents
An Age of Wonder
The Truth About Ukraine
Navigating Complexity
The Supply Chain Problem
The Promise of Dialogue
Too Dumb to Take Care of Ourselves
Extinction Capitalism
Homeless
Republicans Slide Into Fascism
All the Things I Was Wrong About
Several Short Sentences About Sharks
How Change Happens
What's the Best Possible Outcome?
The Perpetual Growth Machine
We Make Zero
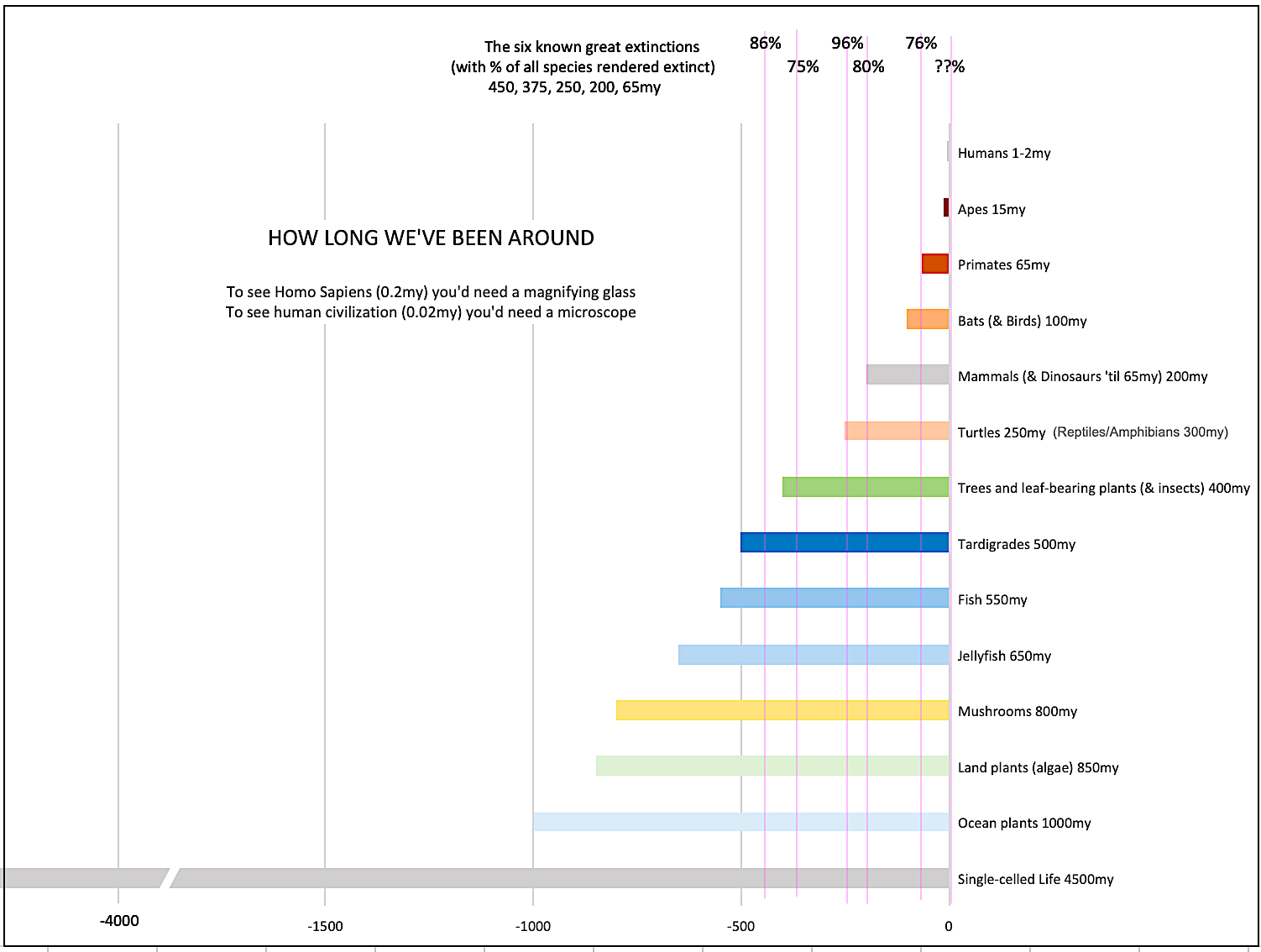
How Long We've Been Around (graphic)
If You Wanted to Sabotage the Elections
Collective Intelligence & Complexity
Ten Things I Wish I'd Learned Earlier
The Problem With Systems
Against Hope (Video)
The Admission of Necessary Ignorance
Several Short Sentences About Jellyfish
Loren Eiseley, in Verse
A Synopsis of 'Finding the Sweet Spot'
Learning from Indigenous Cultures
The Gift Economy
The Job of the Media
The Wal-Mart Dilemma
The Illusion of the Separate Self, and Free Will:
No Free Will, No Freedom
The Other Side of 'No Me'
This Body Takes Me For a Walk
The Only One Who Really Knew Me
No Free Will — Fightin' Words
The Paradox of the Self
A Radical Non-Duality FAQ
What We Think We Know
Bark Bark Bark Bark Bark Bark Bark
Healing From Ourselves
The Entanglement Hypothesis
Nothing Needs to Happen
Nothing to Say About This
What I Wanted to Believe
A Continuous Reassemblage of Meaning
No Choice But to Misbehave
What's Apparently Happening
A Different Kind of Animal
Happy Now?
This Creature
Did Early Humans Have Selves?
Nothing On Offer Here
Even Simpler and More Hopeless Than That
Glimpses
How Our Bodies Sense the World
Fragments
What Happens in Vagus
We Have No Choice
Never Comfortable in the Skin of Self
Letting Go of the Story of Me
All There Is, Is This
A Theory of No Mind
Creative Works:
Mindful Wanderings (Reflections) (Archive)
A Prayer to No One
Frogs' Hollow (Short Story)
We Do What We Do (Poem)
Negative Assertions (Poem)
Reminder (Short Story)
A Canadian Sorry (Satire)
Under No Illusions (Short Story)
The Ever-Stranger (Poem)
The Fortune Teller (Short Story)
Non-Duality Dude (Play)
Your Self: An Owner's Manual (Satire)
All the Things I Thought I Knew (Short Story)
On the Shoulders of Giants (Short Story)
Improv (Poem)
Calling the Cage Freedom (Short Story)
Rune (Poem)
Only This (Poem)
The Other Extinction (Short Story)
Invisible (Poem)
Disruption (Short Story)
A Thought-Less Experiment (Poem)
Speaking Grosbeak (Short Story)
The Only Way There (Short Story)
The Wild Man (Short Story)
Flywheel (Short Story)
The Opposite of Presence (Satire)
How to Make Love Last (Poem)
The Horses' Bodies (Poem)
Enough (Lament)
Distracted (Short Story)
Worse, Still (Poem)
Conjurer (Satire)
A Conversation (Short Story)
Farewell to Albion (Poem)
My Other Sites




{kind=link}
{kind=link}
visit http://manyworlds.com site. The Epiture technology is adaptive with respect to remembering plus other features your readers might find useful. What you want exists; and it’s coming.
It sounds similar to what Microsoft is trying to do with MyLifeBits ( http://research.microsoft.com/barc/mediapresence/MyLifeBits.aspx ), although that’s been in-the-works for quite some time, and I don’t see any mention of capturing web-based output.
why do you think trackbacks didn´t succeed?
cocomment looks good (I do not see how manyworls works for this) but I think it is a bit complicatedwouldn´t it be simpler to search google (or google blogsearch or icerocket,etc) for your name (Daniel won´t do it, but chosing a real special one or adding some code to your text)?do you receive alerts from cocoment when new comments are added?
i agree with you! a need for such a route map is highly important. i am going to try to follow what others has posted as alternative solution.
Have you checked out http://suprglu.com ? It allows you to display feeds from all your stuff in one page. It’s not perfect (still a bit slow) but I quite like it.
why do you think trackbacks didn´t succeed?